Community Articles
- Cloudera Community
- Support
- Community Articles
- Spark Streaming Explained: Kafka to Phoenix
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Created on 04-03-2016 11:10 PM
Data Transformation and Processing with Spark Streaming
This article will describe a little demo application that takes data from Kafka, parses it, does some some aggregations on a different time window and sends the results to Apache Phoenix. Note there is also now a Phoenix Spark plugin available but in this article we will do it the hard way. You can use the same approach to send data to pretty much any target.
Note you can find the sample code about this article in the following repo
https://github.com/benleon/KafkaToPhoenix
Introduction:
Spark provides three main interfaces to work with data which can more or less be transformed into each other:
RDDs:
Spark is built on RDDs, which are distributed datasets that can be recomputed in case of failure and are transient. This means they get only materialized if they are needed, for example to write to a file.
Dataframes:
Dataframes are an abstraction layer on top of RDDs that provide easy SQL style data transformations. They also use an optimizer for optimal joins. Dataframes have the disadvantage of not being typesafe.
Datasets:
Datasets are a new interface that intends to marry the advantages of RDDs and Dataframes.
In this article we will stick with RDDs. They provide a low level access to the data stream and are still the most appropriate layer for developers who have a programming background. They also help to understand how Spark really works.
Working with Spark RDDs:
Spark computes a Execution Graph with transformation operations ( map, filter) and actions ( save, foreach) which actually trigger an execution. Transformation operations are transient and only executed if an action is triggered.
Spark RDDs are distributed datasets with a number of partitions. Spark provides functions to do row level and partition level operations ( map/mapPartition ) on running data. In a similar way there are low level actions which we can use to send our data to Phoenix ( foreachRDD, foreachPartition, foreach ). You will see how they work in the following article.
Closures:
One aspect that makes Spark so powerful is Closures. This means that Spark tries to simulate a single node system by computing the needed objects for each task ( Closure ) and serialize them and sent them to the partitions of the system. This means that you can reference objects relatively freely but you need to keep in mind when they are instantiated and that they need to be Serializable to send them over the network.
Application Description
The demo application will receive a stream of delimited strings from Kafka. The data is from an online cashier system and describes purchases by clients.
ID|DATE|FIRSTNAME|LASTNAME|PRODUCT|AMOUNT 01|2016-04-01 18:20:00|Benjamin|Leonhardi|Coca-Cola|0.89 02|2016-05-02 18:30:00|Klaus|Kinski|Pepsi|0.79 …
We will receive it with a Kafka Direct Stream, parse it into a Scala object then filter and aggregate it and write the aggregated results and the details into two Apache Phoenix tables.
We will have two tables in Phoenix:
SALES , which has all detailed sales
ID, DATE, FIRSTNAME, LASTNAME, PRODUCT, AMOUNT
With the SQL statement:
CREATE TABLE SALES ( ID BIGINT NOT NULL,
DATE DATE,
FIRSTNAME VARCHAR(200),
LASTNAME VARCHAR(200),
PRODUCT VARCHAR(200),
AMOUNT FLOAT
CONSTRAINT PK PRIMARY KEY (ID));PRODUCTSALES, the aggregation table that contains the total revenue per product in 1 min intervals
PRODUCT, DATE, AMOUNT
With the SQL statement:
CREATE TABLE PRODUCTSALES ( PRODUCT VARCHAR(200) NOT NULL, DATE DATE NOT NULL , AMOUNT FLOAT CONSTRAINT PK PRIMARY KEY (PRODUCT, DATE));
Reading from Kafka:
First we need to read the tuples from Kafka, to do this we use the direct Kafka API. We also remove the empty key value from the Stream which leaves us with a single String field containing the delimited Strings.
// create a kafka stream
val kafkaParams = Map[String, String]("metadata.broker.list" -> "sandbox:6667",
"group.id" -> "kafka_phoenix");
val topics = Array("salestopic").toSet;
var directKafkaStream = KafkaUtils.createDirectStream[String, String,
StringDecoder, StringDecoder]
(ssc, kafkaParams, topics)
// first we need to remove the empty key
var inputStream = directKafkaStream.map(_._2);
Repartitioning:
If you read data from Kafka using the Direct approach you get one RDD Partition for each Kafka Partition. If your processing is intense you may want to use repartitioning to increase the parallelity. A good rule of thumb is 2x number of cores on all executors. So if you have 4 core machines and 4 executors on 4 nodes you want 8x4 = 32 partitions. However this obviously depends on what you will be doing. Repartitioning also incurs cost because data is sent over the network between executors. So its a tradeoff.
inputStream = inputStream.repartition(32);
Parsing:
Now we parse the Strings into Row objects. The advantage of RDDs is that you can use any Java object in your Stream. It is good best practice for anything other than simple values or Pairs to define a custom class. Make sure that it is serializable so it can be sent over the network. To be serializable a class needs to extend the Serializable class and all child objects need to be Serializable.
class Row extends Serializable{
var id:Int = 0;
var date:Date = null;
var firstName:String = null;
var lastName:String = null;
var product:String = null
var amount:Double = 0.0d;
}We also need a parser class that uses String split and a SimpleDateFormat to parse the String out. We used Scala in this case:
class Parser {
val dateFormat = new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
def parse(row:String): Row =
{
var parsed = new Row();
var columns = row.split("[|]");
parsed.id = columns(0).toInt;
parsed.date = dateFormat.parse(columns(1));
parsed.firstName = columns(2);
parsed.lastName = columns(3);
parsed.product = columns(4);
parsed.amount = columns(5).toDouble;
return parsed;
}
}Finally we can parse the String into the Row objects using. Note that we use mapPartitions to create one parser object for each Partition so we do not have to create the SimpleDateFormat class in the Parser for every row.
var parsedStream = inputStream.mapPartitions {
rows =>
val parser = new Parser();
rows.map { row => parser.parse(row) }
}
Writing to Phoenix:
First we want to write all rows as they are into the SALES table in Phoenix. We use a Java class in this case called PhoenixForwarder which is a simple implementation of the Phoenix JDBC driver using Prepared Statements to UPSERT the rows into Phoenix. Note that there exists a Phoenix-Spark plugin that handles this as well however you can take the basic template for any kind of data target.
A big advantage of Scala is that it can easily reference Java classes. We will use this PhoenixForwarder here. It has four methods.
- createConnection which opens a JDBC Connection to Phoenix
- sendSales which executes a PreparedStatement against the SALES table
- sendAgg similar to sendSales for the aggregation table
- closeCon this method commits the upserts and closes all connections
public class PhoenixForwarder implements Serializable {
private static final long serialVersionUID = 1L;
String connectionString = "jdbc:phoenix:sandbox.hortonworks.com:2181:/hbase-unsecure:hbase";
Connection con = null;
PreparedStatement prepSales = null;
PreparedStatement prepAgg = null;
public PhoenixForwarder() {
createConnection();
}
public void createConnection() {
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
DriverManager.registerDriver(new PhoenixDriver());
con = DriverManager.getConnection(connectionString);
} catch (Exception e) {
e.printStackTrace();
}
}
public void sendSales(Row row) {
try {
if (prepSales == null) {
String statement = "UPSERT INTO SALES VALUES ( ?, ? , ? , ?, ? , ? )";
this.prepSales = this.con.prepareStatement(statement);
}
prepSales.setInt(1, row.id());
prepSales.setDate(2, new java.sql.Date(row.date().getTime()));
prepSales.setString(3, row.firstName());
prepSales.setString(4, row.lastName());
prepSales.setString(5, row.product());
prepSales.setDouble(6, row.amount());
prepSales.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void sendAgg(String product, Date date, double amount) {
try {
if (prepAgg == null) {
String statement = "UPSERT INTO PRODUCTSALES VALUES ( ?, ?, ? )";
this.prepAgg = this.con.prepareStatement(statement);
}
prepAgg.setString(1, product);
prepAgg.setDate(2, new java.sql.Date(date.getTime()));
prepAgg.setDouble(3, amount);
prepAgg.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
}
public synchronized void closeCon() {
try {
if (con != null)
con.commit();
con.close();
if (prepSales != null)
prepSales.close();
if (prepAgg != null)
prepAgg.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}Now we can use this class to write the sales rows to Phoenix. Note that we use three different methods:
- foreachRDD, this method is specific to Spark Streaming, since a window on a DStream can have multiple RDDs ( of the base size
- foreachPartition, similar to mapPartition this is executed on each Partition of the RDD, we use this to first create our Connection object and then later close it again. Note that we do not have to use one Connection per partition we could also use a connection pool here. ( in each executor )
- foreach, finally the operation that is executed on every row doing the upsert
parsedStream.foreachRDD(
rdd => {
rdd.foreachPartition(rows => {
val phoenixConn = new PhoenixForwarder();
rows.foreach(row => phoenixConn.sendSales(row))
phoenixConn.closeCon();
})
})Aggregating Product sales per minute:
Up until now we wouldn't really need Spark Streaming, any simple tool like Flume could handle what we did until now. However Spark has the advantage of providing window operations, aggregations and Joins. We will use this to aggregate sales by product on a minute basis. First we need to transform our stream into a Pair Stream of the key and the value we want to aggregate. Then we can use the reduceByKeyAndWindow method to aggregate this stream on a new timescale using a simple aggregation function. In this case the function has two values an accumulated value acc and the current value x. For our simple sum this is obviously acc+sum. A more complex function is also available that lets you use a final function ( for example to compute an average:
var reducedStream = parsedStream
.map(record => (record.product, record.amount))
.reduceByKeyAndWindow((acc: Double, x: Double) => acc + x, Seconds(60), Seconds(60))Writing the aggregated Sales to Phoenix:
Now we do the same we did before for the aggregated table with a slight difference. This time we have the two values product and total amount however we need to create a date. We will do this on an RDD level so all partitions will have the same date. You can see Spark Closures in action here. The curDate object will be created on the Driver and serialized and sent to every Partition so each partition will have the same date. Understanding how Closures work is key for effective Spark processing.
reducedStream.foreachRDD(
rdd => {
val curDate = Calendar.getInstance().getTime();
rdd.foreachPartition(rows => {
val phoenixConn = new PhoenixForwarder();
rows.foreach { row => phoenixConn.sendAgg(row._1, curDate, row._2) }
phoenixConn.closeCon();
})
})Building the Application:
Building the application is not quite straightforward. I needed to use the Phoenix-client jar and add it to the sbt lib folder instead of adding dependencies. Also I needed to provide some merge strategies because similar classes are used in the phoenix client jar and kafka/spark.
And this concludes the article. I hope it was useful.
Created on 04-07-2016 10:43 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great Post Ben, learned new things about Phoenix Eliminating Receiver Based Approach is Super Cool and Repartition
Created on 05-24-2016 10:17 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
im facing an error while trying execute the application after compilation capture.png could you correct me if im wrong
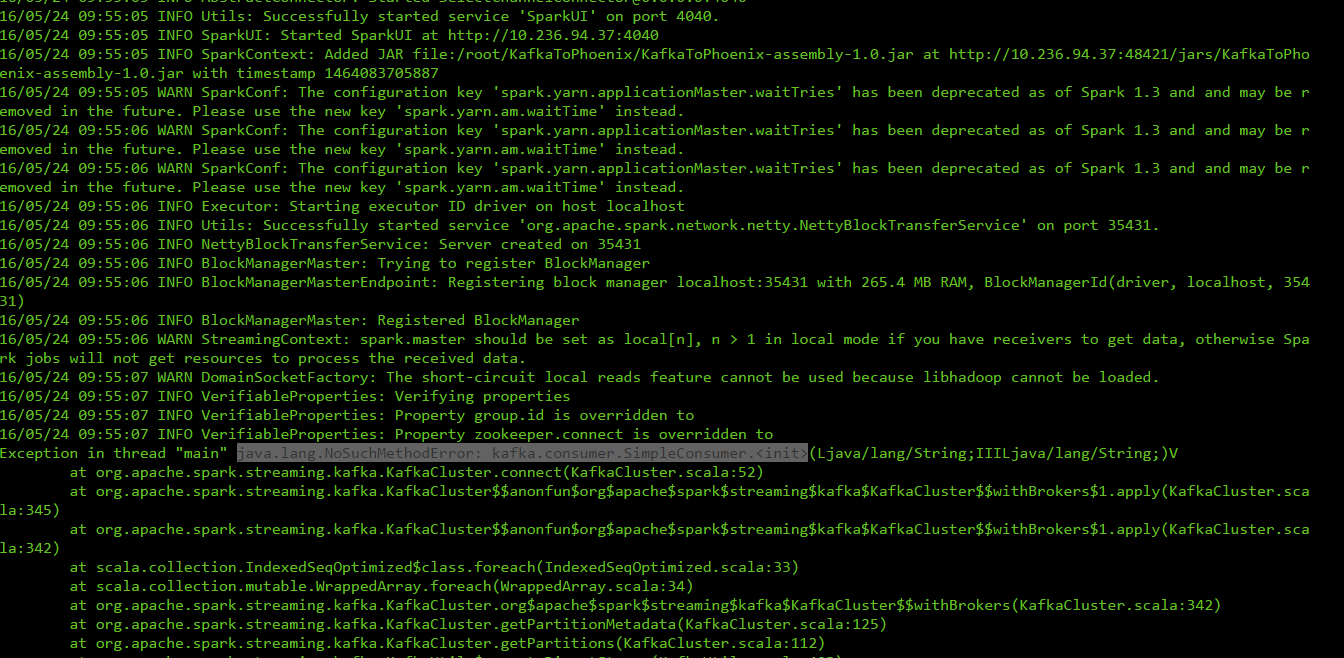{kind=link}
Created on 03-31-2017 02:35 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
great article!

| User | Count |
|---|---|
| 6 | |
| 4 | |
| 2 | |
| 1 | |
| 1 |
