Support Questions
- Cloudera Community
- Support
- Support Questions
- A Typical Requirement in Hadoop
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
A Typical Requirement in Hadoop
- Labels:
-
Apache Hadoop
-
Apache Hive
-
Apache Pig
Created 07-04-2016 10:35 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
I have a typical requirement from one of our client (a beverage company in US).
Requirement is :
In website they have option to show different events , organized in US ,to the customer depending upon the region and member interest.
Table Details in OLTP are as follows ....
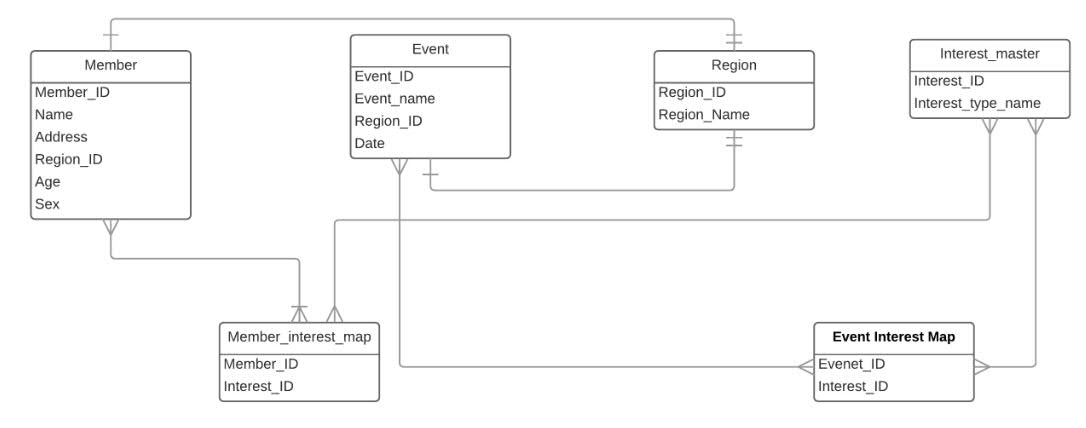{kind=link}
Now Requirement is...
When member logging into the site , we have to find out event name depending on event date , member Interest and region as preferred event for that member.
In general OLTP it takes huge time due to huge load(registered user around 3000000 and Transaction rate around 700 TPS.
We have some other Hadoop based implementation for this application also (like daily sales report in different band , customer update/login frequency etc.) , so we have a ready setup for hadoop (MR,HIVE,PIG) for this client.
Can any one suggest me , how we can handle this typical requirement using hadoop.
Only steps or process is required. I mean the solution designing part or the process only.
Any helps/suggestions will be appreciated...
Please let me know if any one need to know any thing more on requirement or setup about the existing process.
Thanks ....
Created 07-04-2016 11:42 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK for an OLTP requirement and user lookup you are looking at HBase/Phoenix in the HDP distribution ( other possibilities would be Cassandra, Gemfire ... )
HBase is a NoSQL datastore that allows a simple get/put/scan api on flat tables with a unique primary key and arbitrary number of fields.
Phoenix is a SQL layer on top of hbase so its very fast for key lookups/inserts of single rows and can also do aggregations on thousands to millions of rows very efficiently.
Both scale up very well since you can add Region servers dynamically.
Phoenix can maintain secondary indexes as well which might be helpful in your scenario. ( you can obviously directly maintain that in Hbase by adding a translation table and maintaining it yoruself )
Created 07-04-2016 11:42 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
OK for an OLTP requirement and user lookup you are looking at HBase/Phoenix in the HDP distribution ( other possibilities would be Cassandra, Gemfire ... )
HBase is a NoSQL datastore that allows a simple get/put/scan api on flat tables with a unique primary key and arbitrary number of fields.
Phoenix is a SQL layer on top of hbase so its very fast for key lookups/inserts of single rows and can also do aggregations on thousands to millions of rows very efficiently.
Both scale up very well since you can add Region servers dynamically.
Phoenix can maintain secondary indexes as well which might be helpful in your scenario. ( you can obviously directly maintain that in Hbase by adding a translation table and maintaining it yoruself )
Created 07-04-2016 12:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
SnappyData, Apache Ignite and Apache Geode work.

