Support Questions
- Cloudera Community
- Support
- Support Questions
- Consuming Kafka, each Json Messages and write to ...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Consuming Kafka, each Json Messages and write to HDFS as one file?
- Labels:
-
Apache NiFi
Created 02-06-2017 04:05 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Created on 02-06-2017 01:28 PM - edited 08-18-2019 04:50 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You will want to stick with the "Bin-Packing Algorithm" merge strategy in your case. The reason you are ending up with single files is because of the way the MergeContent processor is designed to work. There are several factors in play here:

As the MergeContent processor will start the content of each new FlowFile on a new line. However, at times the incoming content of each FlowFile may be multiple lines itself. So it may be desirable to put a user defined "Demarcator" between the content of each FlowFile should you need to differentiate the content of each merge at a later time. If that is the case, the MergeContent processor provides a "Demarcator" property to accomplish this.
An UpdateAttribute processor can be used following the MergeContent processor to set a new "filename" on the resulting merged FlowFile. I am not sure the exact filename format you want to use, but here is an example config that produce a filename like "2017-02-06":

Thanks,
Matt
Created 02-06-2017 05:16 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you update your minimum number of entries to what you want at minimum, let's say 500 files. Also since it's all similar data going into one file, I am assuming flow file attributes are same. Can you change your merge strategy to defragment?
Finally I am your flow is something like this:
consumeKafka -> mergecontent -> putHDFS
Is that right?
Created 02-06-2017 01:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The "defragment" merge strategy can only be used to Merge files that have very specific attributes assigned to them. That strategy is typically used to reassemble a FlowFile that was previously split apart by NiFi.
Created on 02-06-2017 10:09 AM - edited 08-18-2019 04:50 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Naresh Kumar Korvi You want it to look a bit like this:
- Note the header, footer, and demarcator - this will aggregate your json records into a properly formatted document for later reading
- Set a max bin age so the final few messages will not get stuck in the queue
- Set a min size and min number of entires to stop lots of little files being written
- Set a max size and max entries that generate a file of the size you want to work with
- Play with the values a bit using the GenerateFlowfile processor to create appropriately sized content to test with if your Kafka dataflow is a bit slow.
- Your flow should be ConsumeKafka -> MergeContent -> UpdateAttribute (set filename, path) -> PutHDFS

Created 02-06-2017 10:27 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Created on 02-06-2017 01:28 PM - edited 08-18-2019 04:50 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You will want to stick with the "Bin-Packing Algorithm" merge strategy in your case. The reason you are ending up with single files is because of the way the MergeContent processor is designed to work. There are several factors in play here:
As the MergeContent processor will start the content of each new FlowFile on a new line. However, at times the incoming content of each FlowFile may be multiple lines itself. So it may be desirable to put a user defined "Demarcator" between the content of each FlowFile should you need to differentiate the content of each merge at a later time. If that is the case, the MergeContent processor provides a "Demarcator" property to accomplish this.
An UpdateAttribute processor can be used following the MergeContent processor to set a new "filename" on the resulting merged FlowFile. I am not sure the exact filename format you want to use, but here is an example config that produce a filename like "2017-02-06":
Thanks,
Matt
Created 02-06-2017 10:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
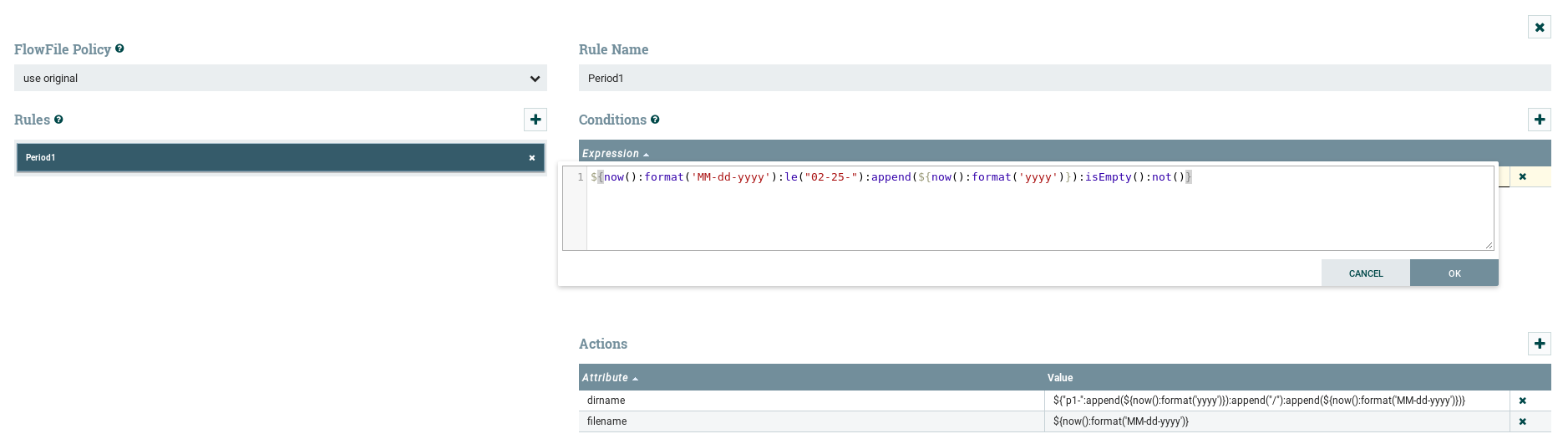
Thanks Matt, this is some kind of similar i'm looking at. but also how do i create dir based on date condition.
For Example: Based on date range it should create a dir dynamically.
this is what i'm expecting the dir structure to be:
period1-year/p1-week1/date/date.json
I'm not sure if i have the right condition in updateattribute.
Created on 02-07-2017 02:26 PM - edited 08-18-2019 04:50 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The "Conditions" specified for your rule must result in a boolean "true" before the associated "Actions" will be applied against the incoming FlowFile. Your condition you have in the screenshot will always resolve to true...

Looking at your "dirname" attribute, it is not going to return your desired directory path of:
period1-year/p1-week1/date
and your "filename" attribute will be missing the .json extension you are looking for as well:
date.json
I believe what you are trying to do is better accomplished using the below "Condition" and "Action" configurations:

Condition:
${now():format('MM'):le(2):and(${now():format('dd'):le(25)})}dirname:
period1-${now():format('yyyy')}/p1-${now():format('ww')}/${now():format('MM-dd-yyyy')}filename:
${now():format('MM-dd-yyyy')}.json
{kind=link}
{kind=link}
Thanks,
Matt
Created 02-10-2017 03:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Matt
Thanks, Matt this is something i was looking at.

