Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Does jar files missing for spark interpreter?
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Does jar files missing for spark interpreter?
- Labels:
-
Apache Hive
-
Apache Spark
-
Apache Zeppelin
Created 02-22-2017 02:12 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I am facing a strange behaviour in sparK;
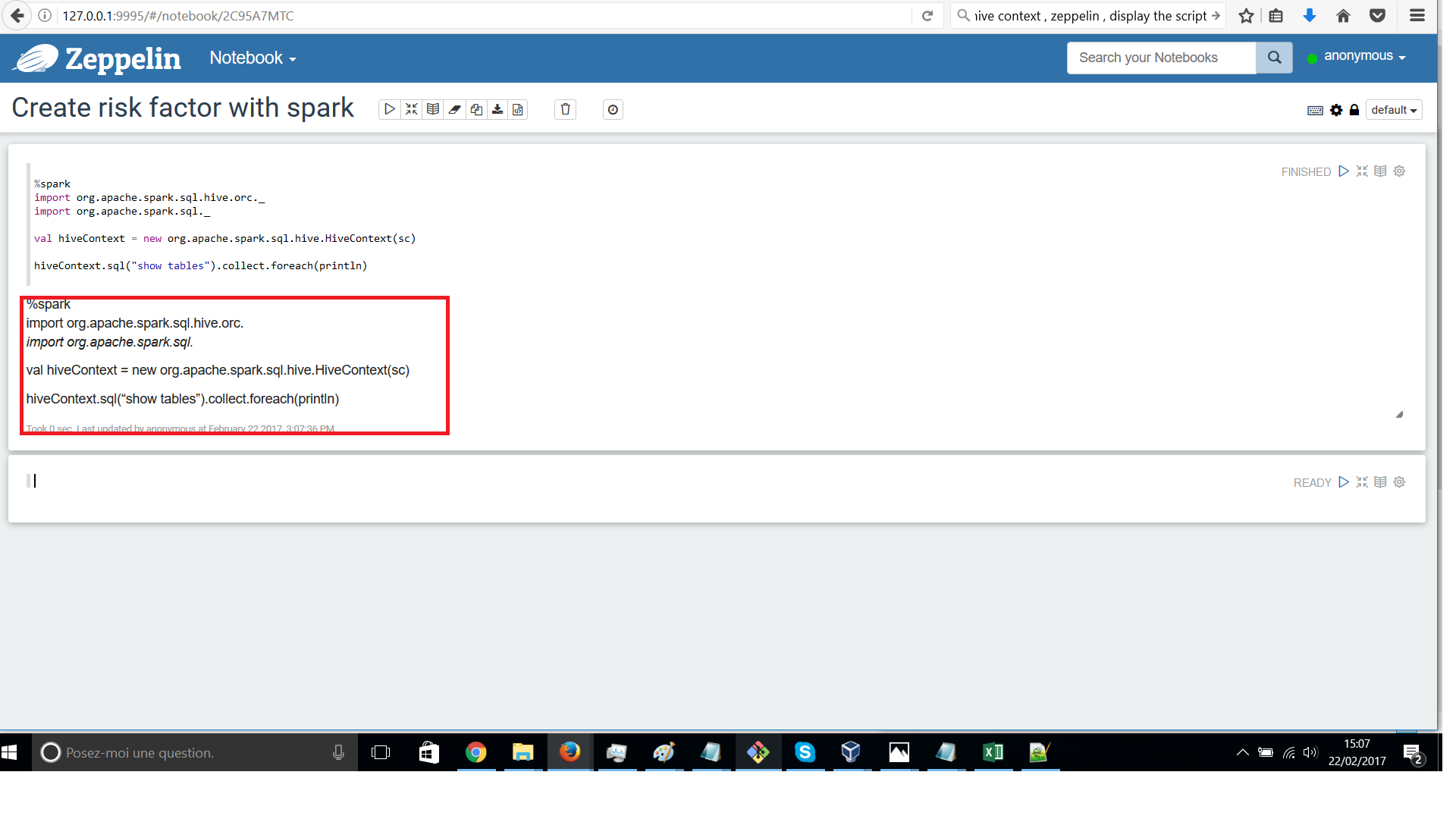
I am following the tutotial (lab 4 -spark analysis) but when executing the command the script is returned as you can see on the picture(red rectangle)
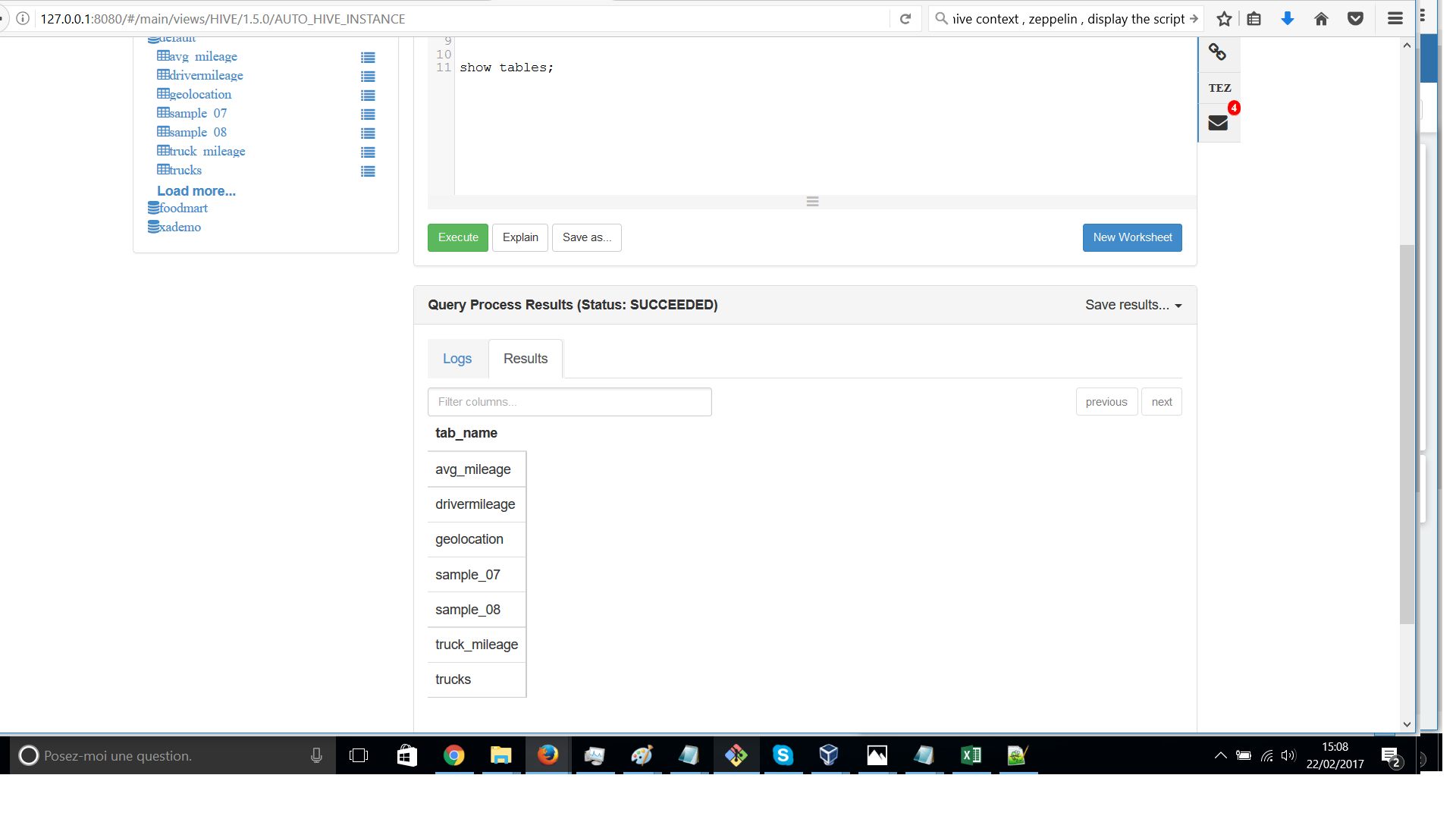
I have tables in My hive database default.
I checked the jar files in my spark interpreter and found jar files as you can see on picture sparkjarfiles.png (Are some jar files missing please?
Any suggestion?hivedisplay.pnghicecontextdisplay.png
Created 02-23-2017 06:59 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you provide the following:
1. As @Bernhard Walter already asked, can you attach the screenshot of your spark interpreter config from Zeppelin UI
2. Create a new Notebook and run the below and send the output:
%sh whoami
3. Can you attach the output of
$ ls -lrt /usr/hdp/current/zeppelin-server/local-repo
4. Is your cluster Kerberized?
Created 02-22-2017 02:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By any chance do you have any extra line before the "%spark" or if there is any special character (my be while copying and pasting it might have come). Can you manually write those lines of %spark script freshly and then test again?
Created on 02-22-2017 02:45 PM - edited 08-19-2019 03:33 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

Ideally it should work.
Created 02-22-2017 02:47 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
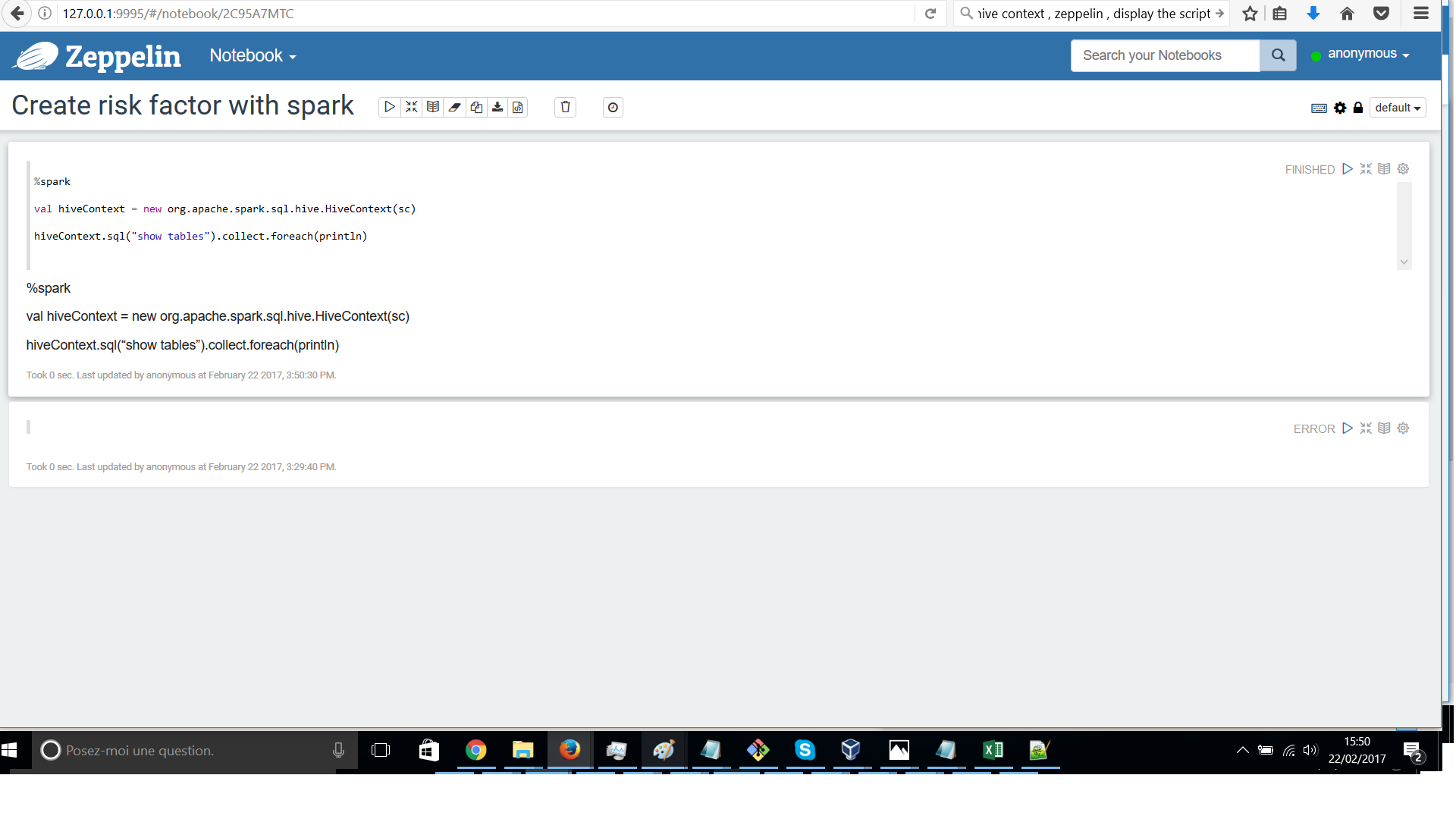
Hi @Jay,
I checked but no extra line before "%spark"
I manually write but still facing the problemhicecontextdisplay-2.png
Created 02-22-2017 02:39 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Side note: in HDP Zeppelin sqlContext defaults to hiveContext. So something like
%spark
sqlContext.sql("show tables").collect.foreach(println)should work.
Alternatively:
%sql show tables
As Jay mentioned, the % needs to be in the first line
Created 02-22-2017 02:59 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @Bernhard, I have tried both but facing the same problem.
Maybe jar files missing in my spark interpreter?
Created 02-22-2017 03:44 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does Zeppelin send to Spark Interpreter at all?
What is
%spark print(sc.version)
printing? No hiveContext necessary
Created 02-23-2017 08:54 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
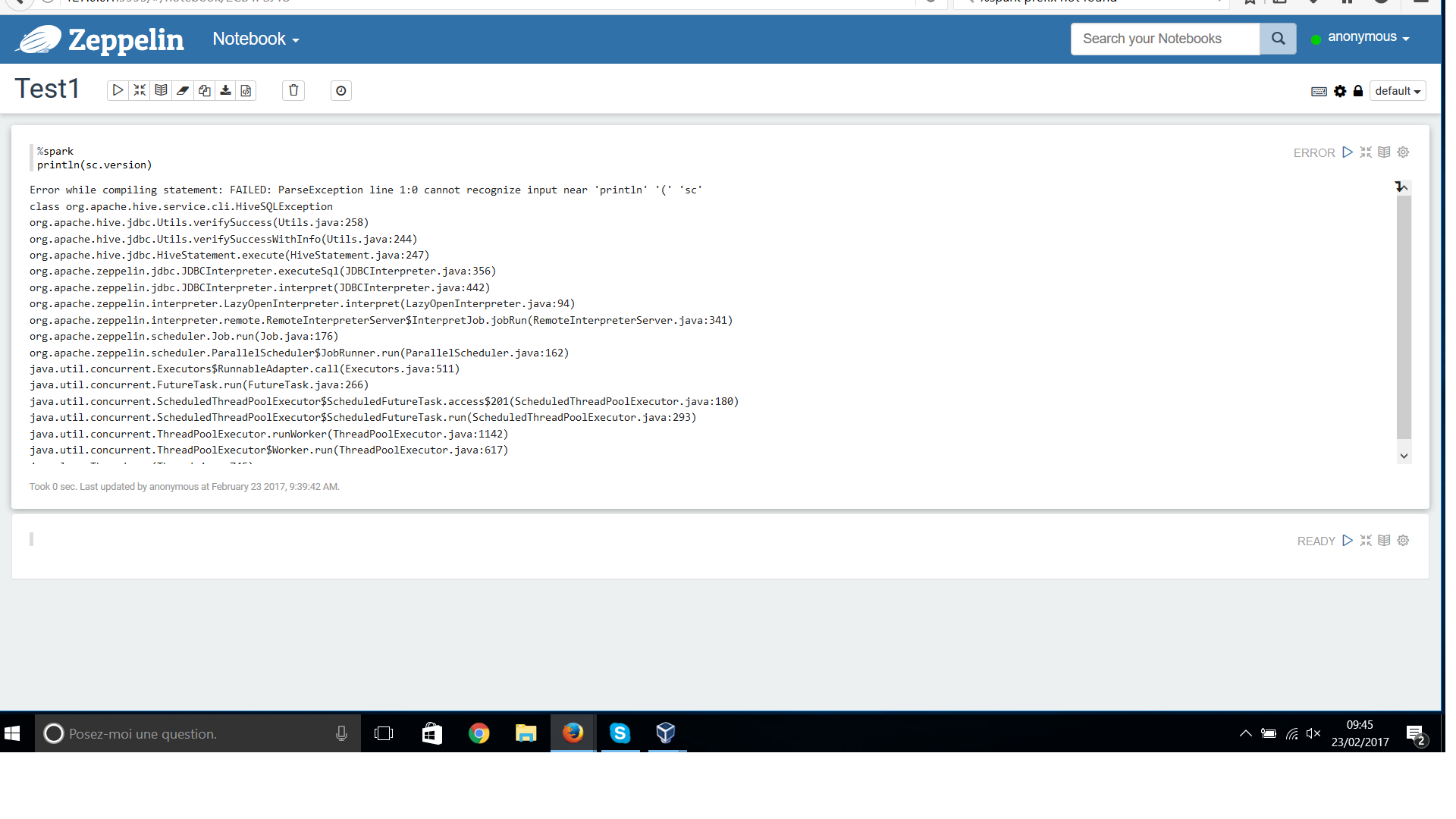
Hi @Bernhard, Excuse me not to have respected what you said before concerning the fisrt line.
the interpreter %jdbc(hive) and %sql are working well because the "show tables" display the result expected.
The problem i have is with %spark(respecting the first line) and I have errors as you can see on the joined picture.
In the interpreter binding, I have selected spark and save
I joined also the spark interpreter configuration
Created on 02-22-2017 03:54 PM - edited 08-19-2019 03:33 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
and what are the Interpreter settings saying. Here are mine.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
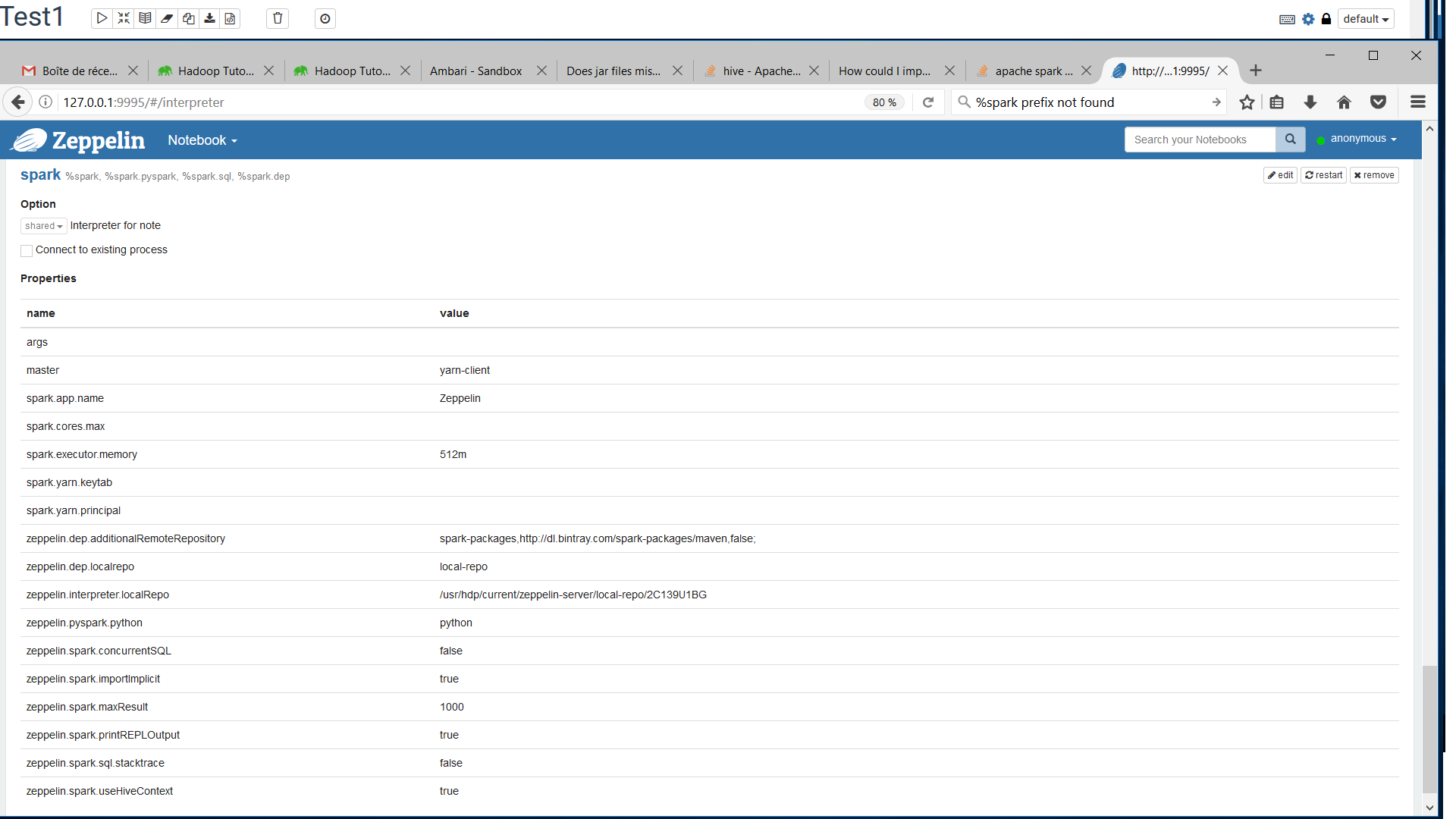{kind=link}
Note: a simple "python" in zeppelin.pyspark.python is also OK.
... by the way, I have the same libs in my zeppelin libs spark folder.
Have you tried to restart the interpreter?
Created 02-23-2017 06:59 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you provide the following:
1. As @Bernhard Walter already asked, can you attach the screenshot of your spark interpreter config from Zeppelin UI
2. Create a new Notebook and run the below and send the output:
%sh whoami
3. Can you attach the output of
$ ls -lrt /usr/hdp/current/zeppelin-server/local-repo
4. Is your cluster Kerberized?

