Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Frequent shutdown of datanodes
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Frequent shutdown of datanodes
- Labels:
-
Apache Hadoop
Created 07-15-2017 02:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have a cluster running HDP 2.5 with 3 worker nodes. Recently two of our datanodes go down frequently - usually they both go down at least once a day, frequently more often than that. While they can be started up without any difficulty, they will usually fail again within 12 hours. There is nothing out of the ordinary in the logs except very long GC wait times before failure. For example, shortly before failing this morning, I saw the following in the logs:
i set datanode heap size to 16 gb and new generation to 8 gb.
please help...
<br>
Created 07-16-2017 09:36 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@jsensharma
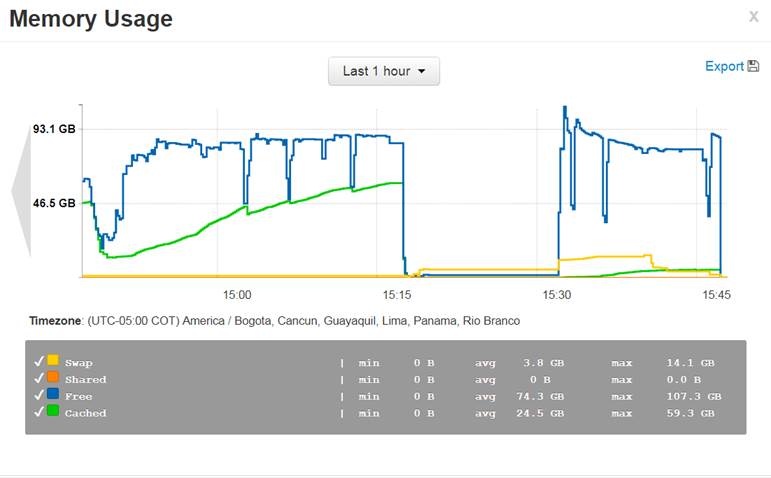
What I found curious is that the Cached Mem grew a lot just before the node stopped sending heartbeats. Do you know why would that be? cache.jpg
{kind=link}
Created 07-16-2017 09:44 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@jsensharma
what is the recommendation for Datanode heap size and new generation heap size?
now i set datanode heapsize to 24 GB and new genreration heap size to 10 GB.
Created 07-16-2017 11:38 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
2017-07-15T13:50:33.501-0500: 4009.839: [Full GC (Allocation Failure) 2017-07-15T13:50:33.501-0500: 4009.840: [CMS2017-07-15T13:50:39.567-0500: 4015.905: [CMS-concurrent-mark: 12.833/12.841 secs] [Times: user=20.33 sys=5.59, real=12.84 secs] (concurrent mode failure): 14680064K->14680064K(14680064K), 39.2851287 secs] 24117247K->22948902K(24117248K), [Metaspace: 36771K->36771K(1083392K)], 39.2852865 secs] [Times: user=39.18 sys=0.04, real=39.29 secs] . 2017-07-15T13:52:15.250-0500: 4111.588: [Full GC (Allocation Failure) 2017-07-15T13:52:15.250-0500: 4111.588: [CMS2017-07-15T13:52:21.412-0500: 4117.750: [CMS-concurrent-mark: 12.025/12.030 secs] [Times: user=17.74 sys=1.38, real=12.03 secs] (concurrent mode failure): 14680063K->14680063K(14680064K), 39.5266803 secs] 24117247K->23076661K(24117248K), [Metaspace: 36781K->36781K(1083392K)], 39.5268469 secs] [Times: user=39.41 sys=0.05, real=39.53 secs]
.
We see that out of 24GB almost all 24GB is being utilized by the DataNode and the Garbage collector is hardly able to clean up the 1 GB memory.
24117247K->22948902K(24117248K) AND 24117247K->23076661K(24117248K)
It indicates that the Heap Size is not sufficient for the DataNode or the DataNode cache settings are not appropriately set.
- Can you please share the core-site.xml and hdfs-site.xml
- Some issues are reported for similar behavior: https://issues.apache.org/jira/browse/HDFS-11047
.
Created 07-17-2017 07:31 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@jsensharma,
did you check hdfs-site.xml,,,core-site.xml?please have a look and let me know if any changes needded.
Created 07-18-2017 12:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@jsensharma,@nkumar,
We have a cluster running HDP 2.5 with 3 worker nodes and around 9.1 million blocks with an average block size of 0.5 MB.Is could be the reason for frequent JVM pause ?
Created 07-20-2017 05:44 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Srinivas,
Does all your datanode is affected by this issues / SIngle DataNode is only affected. Have u tried to re-balance HDFS to see if issue is fixed.
Created 07-20-2017 05:47 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
All 3 datanodes going down frequently..The datanodes are going down one after the other, quite seemingly, one of the node gets hit harder than the rest.
- « Previous
-
- 1
- 2
- Next »

