Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Hi team , hive job taking so much time compare...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Hi team , hive job taking so much time compare to last run(since 20hour it is running)same job last run it was completed on 30min ..Please help me to exit from this issue
- Labels:
-
Apache Hadoop
-
Apache Hive
-
Apache Tez
Created 06-08-2017 07:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
job-status.pngHi team,
{kind=link}
I am using hive with tez in HDP and i am running hive query,it was completed 99.27% and it is stuck in reducer phase, attached the screenshot.
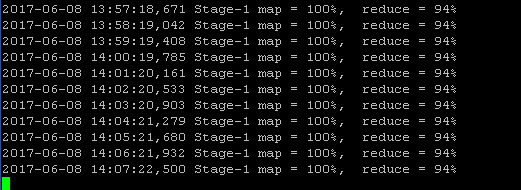{kind=link}
{kind=link}
{kind=link}
same job was done in 30min in last run, please suggest why it is happen and solution for this issue?
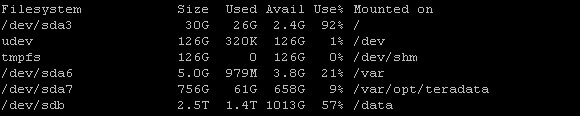
i have below memory space in linux :swap
total used free shared buffers cached
Mem: 258041 254721 3320 0 3449 237158
-/+ buffers/cache: 14114 243927 Swap: 49151 660 48491
Please suggest
Created 06-10-2017 09:53 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @rama , First of all, I would suggest you to kill such jobs after 2-2.5 Hours, especially when your job finishes in half n hour on a normal day.
1 probable cause could be any other job is utilizing 90+% CPU, hence slowing down your job process.
If you can provide me your entire query, I may be able to provide you few set parameters which will help running the query faster.
Cheers, Sagar
Created 06-10-2017 10:45 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
currently no other job are running except this job,actually it was stuck at 97.22% and when i kill the job and rerun again it was stuck same position , last reducer was running forever.
up to table creation and insert the values into drome_master_5 it was good but while insert value into .drome_master_6 it was stuck.
below is step where the query stuck
insert into table dropme_master_6 select * from dropme_master_5 where dropme_master_5.consumer_sequence_id not in ( select consumer_sequence_id from dropme_master_6);
and while executing the this step it shows below warning message
Warning: Map Join MAPJOIN[30][bigTable=dropme_master_5] in task 'Map 4' is a cross product
i was split query and execute it like below and it gave result very fast
select count(consumer_sequence_id) from dropme_master_6;
result:10352059
select count(*) from dropme_master_5;
OK
21287539
i have added below parameter to the job but no use
set hive.execution.engine=mr;
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
set hive.tez.container.size=10240;
set hive.tez.java.opts=-Xmx9216m;
set mapreduce.map.memory.mb=8192;
set mapreduce.map.java.opts=-Xmx7372m;
set mapreduce.reduce.memory.mb=9216;
set mapreduce.reduce.java.opts=-Xmx8294m;
set yarn.scheduler.minimum-allocation-mb=1024;
set yarn.scheduler.maximun-allocation-mb=11264;
set hive.cbo.enable=true;
{kind=link}
{kind=link}
Created 06-12-2017 01:48 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @rama ,
Please change your query to this:
insert into table dropme_master_6 select * from dropme_master_5 a left outer join dropme_master_6 b on a.consumer_sequence_id = b.consumer_sequence_id where b.consumer_sequence_id is null;
I am pretty confident this will improve your performance.
Please let me know if it works and give me a thumps up. 🙂
Regards,
Sagar Morakhia
Created 06-12-2017 09:35 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @rama
The below query will make your query run faster.
insert into table dropme_master_6 select * from dropme_master_5 a left outer join dropme_master_6 b on a.consumer_sequence_id = b.consumer_sequence_id where b.consumer_sequence_id is null;
Created 06-13-2017 12:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks you @Sagar Morakhia
I have try above query but no luck still it is running since 4 hours

