Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Is it possible to use S3 for Falcon feeds?
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Is it possible to use S3 for Falcon feeds?
- Labels:
-
Apache Falcon
Created 09-06-2016 10:29 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have not seen any example of using s3 in Falcon except for mirroring. Is it possible to use an S3-bucket as location path for a feed?
Created 09-06-2016 11:49 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Liam Murphy: Please find the details below
1> Ensure that you have an Account with Amazon S3 and a designated bucket for your data
2> You must have an Access Key ID and a Secret Key
3> Configure HDFS for S3 storage by making the following changes to core-site.xml
<property> <name>fs.default.name</name> <value>s3n://your-bucket-name</value> </property> <property> <name>fs.s3n.awsAccessKeyId</name> <value>YOUR_S3_ACCESS_KEY</value></property> <property> <name>fs.s3n.awsSecretAccessKey</name> <value> YOUR_S3_SECRET_KEY </value> </property>
4>In the falcon feed.xml, specify the Amazon S3 location and schedule the feed
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<feed name="S3Replication" description="S3-Replication" xmlns="uri:falcon:feed:0.1">
<frequency>
hours(1)
</frequency>
<clusters>
<cluster name="cluster1" type="source">
<validity start="2016-09-01T00:00Z" end="2034-12-20T08:00Z"/>
<retention limit="days(24)" action="delete"/>
</cluster>
<cluster name="cluster2" type="target">
<validity start="2016-09-01T00:00Z" end="2034-12-20T08:00Z"/>
<retention limit="days(90)" action="delete"/>
<locations>
<location type="data" path="s3://<bucket-name>/<path-folder>/${YEAR}-${MONTH}-${DAY}-${HOUR}/"/>
</locations>
</cluster>
</clusters>
Created 09-06-2016 11:11 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Document exists for wasb http://falcon.apache.org/DataReplicationAzure.html, may be just use s3a instead.
Created 09-06-2016 11:49 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Liam Murphy: Please find the details below
1> Ensure that you have an Account with Amazon S3 and a designated bucket for your data
2> You must have an Access Key ID and a Secret Key
3> Configure HDFS for S3 storage by making the following changes to core-site.xml
<property> <name>fs.default.name</name> <value>s3n://your-bucket-name</value> </property> <property> <name>fs.s3n.awsAccessKeyId</name> <value>YOUR_S3_ACCESS_KEY</value></property> <property> <name>fs.s3n.awsSecretAccessKey</name> <value> YOUR_S3_SECRET_KEY </value> </property>
4>In the falcon feed.xml, specify the Amazon S3 location and schedule the feed
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<feed name="S3Replication" description="S3-Replication" xmlns="uri:falcon:feed:0.1">
<frequency>
hours(1)
</frequency>
<clusters>
<cluster name="cluster1" type="source">
<validity start="2016-09-01T00:00Z" end="2034-12-20T08:00Z"/>
<retention limit="days(24)" action="delete"/>
</cluster>
<cluster name="cluster2" type="target">
<validity start="2016-09-01T00:00Z" end="2034-12-20T08:00Z"/>
<retention limit="days(90)" action="delete"/>
<locations>
<location type="data" path="s3://<bucket-name>/<path-folder>/${YEAR}-${MONTH}-${DAY}-${HOUR}/"/>
</locations>
</cluster>
</clusters>
Created 09-08-2016 11:35 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for that Sowyma,
This is definitely trying to do something! But I now see an exception in oozie logs which says
160908110420441-oozie-oozi-W] ACTION[0000034-160908110420441-oozie-oozi-W@eviction] Launcher exception: com.amazonaws.AmazonClientException: Unable to load AWS credentials from any provider in the chain
org.apache.oozie.action.hadoop.JavaMainException: com.amazonaws.AmazonClientException: Unable to load AWS credentials from any provider in the chain
at org.apache.oozie.action.hadoop.JavaMain.run(JavaMain.java:59)
at org.apache.oozie.action.hadoop.LauncherMain.run(LauncherMain.java:47)
..
Created 09-07-2016 12:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see that Sowmya already answered. Yes, we can specify S3 as the source/destination cluster(s) with paths (we support Azure as well). Here is a Falcon screenshot.
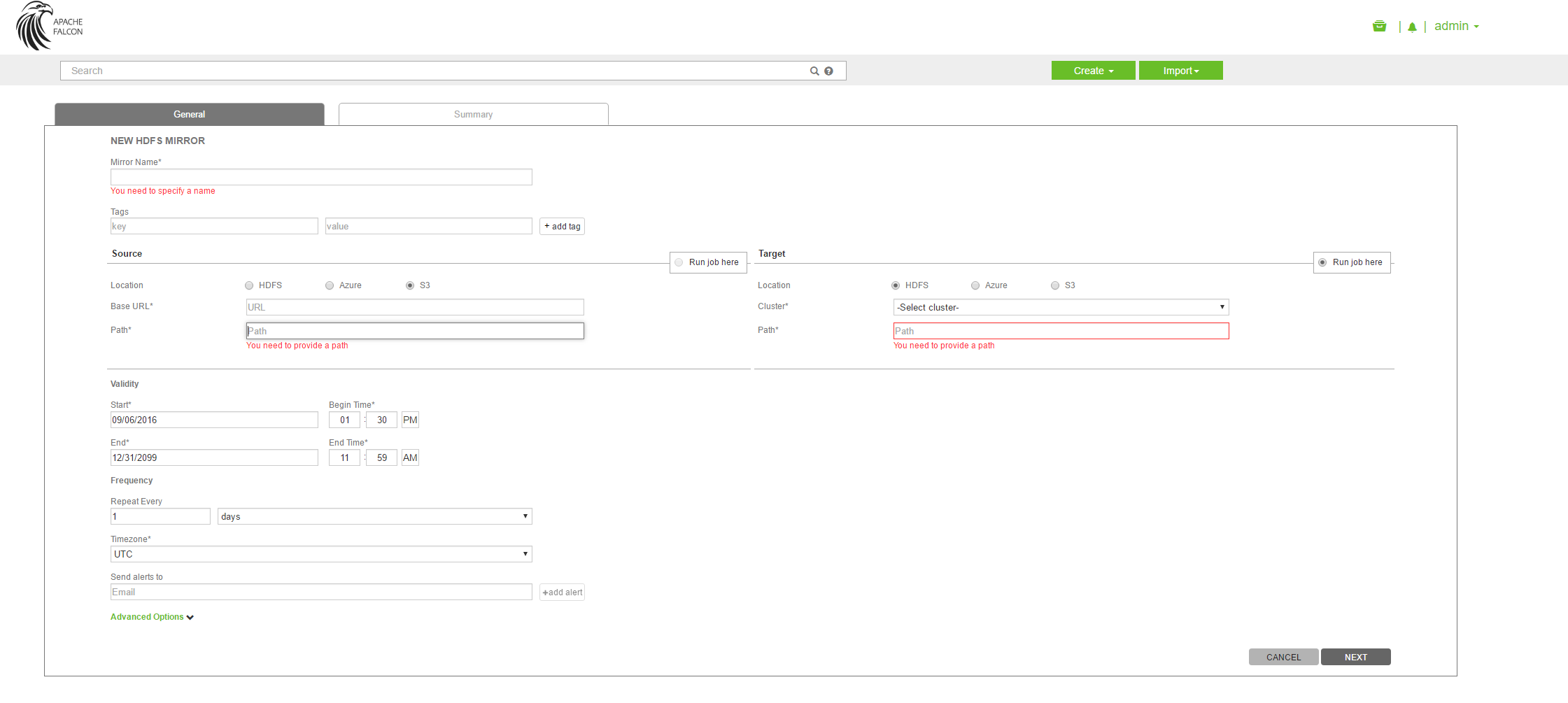{kind=link}
Created 09-08-2016 12:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Full exception in oozie log is as follows:
org.apache.oozie.action.hadoop.JavaMainException: com.amazonaws.AmazonClientException: Unable to load AWS credentials from any provider in the chain
at org.apache.oozie.action.hadoop.JavaMain.run(JavaMain.java:59)
at org.apache.oozie.action.hadoop.LauncherMain.run(LauncherMain.java:47)
at org.apache.oozie.action.hadoop.JavaMain.main(JavaMain.java:35)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.oozie.action.hadoop.LauncherMapper.map(LauncherMapper.java:236)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:453)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: com.amazonaws.AmazonClientException: Unable to load AWS credentials from any provider in the chain
at com.amazonaws.auth.AWSCredentialsProviderChain.getCredentials(AWSCredentialsProviderChain.java:117)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:3521)
at com.amazonaws.services.s3.AmazonS3Client.headBucket(AmazonS3Client.java:1031)
at com.amazonaws.services.s3.AmazonS3Client.doesBucketExist(AmazonS3Client.java:994)
at org.apache.hadoop.fs.s3a.S3AFileSystem.initialize(S3AFileSystem.java:297)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2653)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:92)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2687)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2669)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:371)
at org.apache.falcon.hadoop.HadoopClientFactory$1.run(HadoopClientFactory.java:200)
at org.apache.falcon.hadoop.HadoopClientFactory$1.run(HadoopClientFactory.java:198)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.falcon.hadoop.HadoopClientFactory.createFileSystem(HadoopClientFactory.java:198)
at org.apache.falcon.hadoop.HadoopClientFactory.createProxiedFileSystem(HadoopClientFactory.java:153)
at org.apache.falcon.hadoop.HadoopClientFactory.createProxiedFileSystem(HadoopClientFactory.java:145)
at org.apache.falcon.entity.FileSystemStorage.fileSystemEvictor(FileSystemStorage.java:317)
at org.apache.falcon.entity.FileSystemStorage.evict(FileSystemStorage.java:300)
at org.apache.falcon.retention.FeedEvictor.run(FeedEvictor.java:76)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.falcon.retention.FeedEvictor.main(FeedEvictor.java:52)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.oozie.action.hadoop.JavaMain.run(JavaMain.java:56)
... 15 more
I have defined fs.s3a.acccess.key, fs.s3a.secret.key, fs.s3a.endpoint in hdfs-stite.xml. I can use hdfs dfs -ls s3a://<my-buckt> from the command line, and it works. I've also set the path in the feed example to be s3a://<my-bucket>...
But this exception would seem to day oozie can't see the AWS access/secret key from some reason?
Regards,
Liam
Created 09-08-2016 06:14 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you are using multiple clusters, you need to make sure that the hadoop configuration that Oozie uses for the target cluster (see oozie.service.HadoopAccessorService.hadoop.configurations property in oozie-site.xml) is correctly configured. By default in a single cluster environment, Oozie will point to the local core-site.xml for this by default
Created 09-08-2016 07:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Venkat,
The property is set to *=/etc/hadoop/conf. This is just a simple single node cluster (HDP 2.3 sandbox). The s3a properties have been added to both core and hdfs site files, but still the same problem I'm afraid.
Created 09-08-2016 07:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Liam Murphy: Can you attach the Feed xml and Falcon and oozie logs? Looks like eviction is failing. Can you see if the replication succeeded? Oozie bundle created will have one for retention and another for replication. Thanks!
Created 09-12-2016 10:14 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sowmya,
Attached file contains the feed definition, falcon and oozie logs. I submitted and scheduled the feed around the 14:40
timestamp
Thanks for your help
Liam

