Support Questions
- Cloudera Community
- Support
- Support Questions
- LLAP not using io cache
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
LLAP not using io cache
- Labels:
-
Apache Hive
-
HDFS
Created on 02-21-2017 07:21 AM - edited 09-16-2022 04:07 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I've setup LLAP and it is working fine, but it is not using the IO Cache. I've set the below in both the CLI and HS2, but Grafana shows no cache used (and HDFS name node is very busy keeping the edits). Any ideas on what I might be missing?
--hiveconf hive.execution.mode=llap
--hiveconf hive.llap.execution.mode=all
--hiveconf hive.llap.io.enabled=true
--hiveconf hive.llap.daemon.service.hosts=@llap0
Created 02-21-2017 09:38 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there a typo n your question above? You mention hive.llap.iomemory.mode.cache
Correct is: set hive.llap.io.memory.mode=cache
Just checking before moving forward.
What makes me to believe is a typo is that you stated that it was null which is not correct. The default is actually "cache". That makes me to believe that you mistyped the variable.
Created 02-21-2017 02:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update for those out there thinking of answer, (and a cheat sheet for those browsing of good parameters to set - I have tested each individually and have response time down to 630ms and throughput to 40 queries/sec for a 1Tb dataset, but need to get the iocache going to get to the next level and improve throughput (q/sec)):
The io cache is created (12Gb), but is never used.
I am using OOTB LLAP settings except for below changes, all of which were positive in driving down response time and increasing throughput, except a few were neutral:
-increased mem for yarn, llap heap, llap concurrency
-disabled CBO (it's adding time to query during creating and submitting plan portion of query)
-set hive.llap.iomemory.mode=cache (OOTB this setting was null)
-increased /proc/sys/net/core/somaxconn to 4096
-increase metastore heap
-increased yarn threads (yarn.resourcemanager.amlauncher.thread-count)
-increased Yarn Resource Manager heartbeat interval (tez.am-rm.heartbeat.interval-ms.max)
-set hive.llap.daemon.vcpus.per.instance to 32, previously it is unrecognized variable (ambari bug) and gave message in ambari startup of "WARN conf.HiveConf: HiveConf hive.llap.daemon.vcpus.per.instance expects INT type value"
-added additional HS2 instance.
-added the 4 hive-conf options (hive.execution.mode, hive.llap.execution.mode, hive.lllap.io.enabled, hive.llap.daemon.service.host.) as additional properties in HS2 custom site.
-increased HDFS heap
Version of HDP is 2.5.3.0-37
Version of Hive is 2.1.0.2.5.3.0-37
Created 02-21-2017 08:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Created 02-21-2017 09:38 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there a typo n your question above? You mention hive.llap.iomemory.mode.cache
Correct is: set hive.llap.io.memory.mode=cache
Just checking before moving forward.
What makes me to believe is a typo is that you stated that it was null which is not correct. The default is actually "cache". That makes me to believe that you mistyped the variable.
Created 02-21-2017 09:41 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes, typo in post. it is hive.llap.io.memory.mode=cache
Thanks!
Created 02-21-2017 09:49 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok. Still not explaining that you noticed that variable default value other than "cache". That is the default.
How is hive.llap.io.enabled? By default is null. Try with true.
Created 02-21-2017 10:12 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
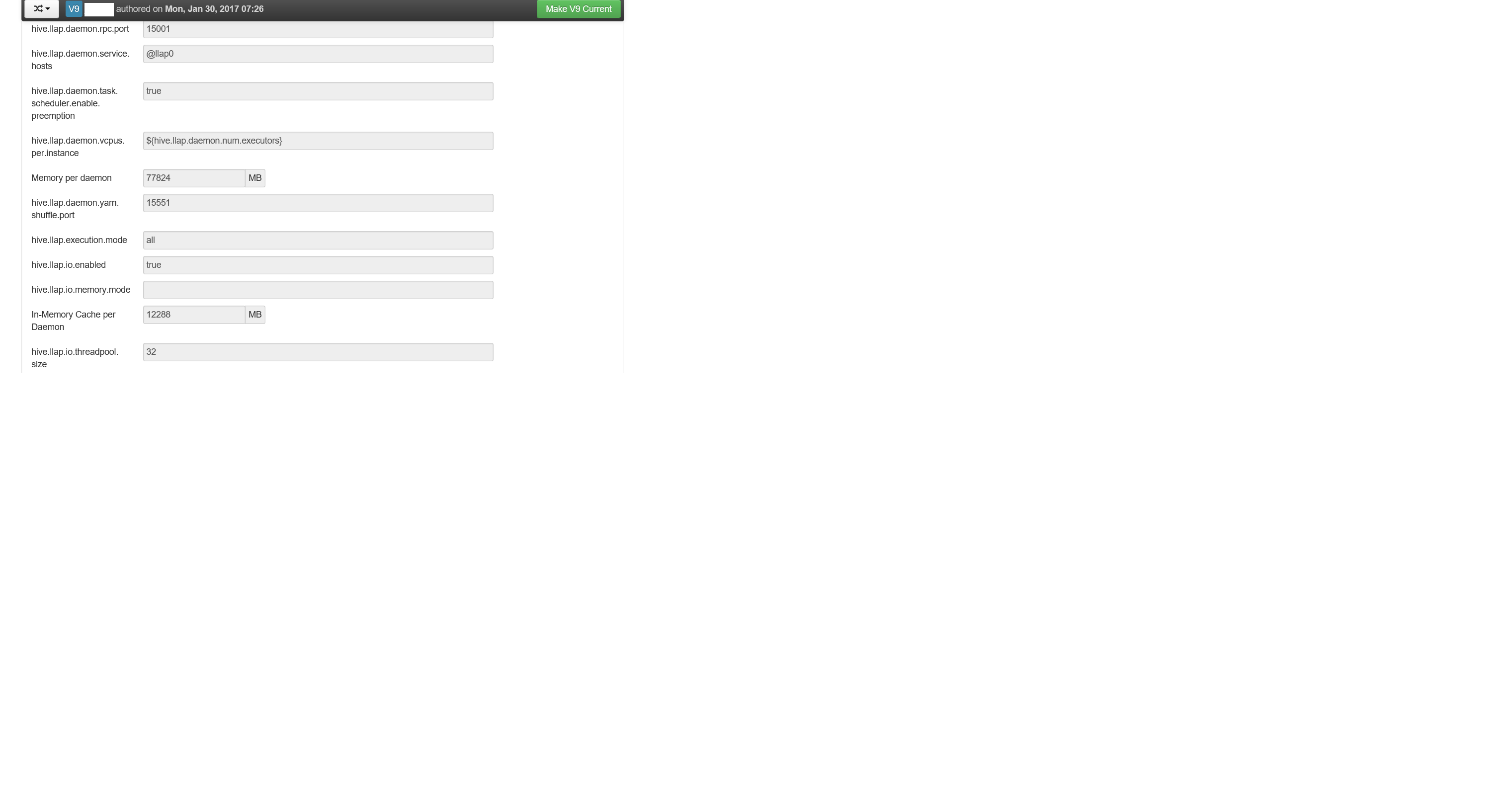{kind=link}
Yeah, I thought so too. It was literally blank (see screenshot of first ambari version post enabling interactive query). Also odd was the hive.llap.daemon.vcpus.per.instance, it was a variable rather than the number. This generated a WARN at start ("WARN conf.HiveConf: HiveConf hive.llap.daemon.vcpus.per.instance expects INT type value"). So I put 32 in for the vcpu's and I put cache for hive.llap.io.memory.mode. They saved correctly to hive-site.xml.
The third anamoly is I get is a message that says "WARN conf.HiveConf: HiveConf of name hive.llap.daemon.allow.permanent.fns does not exist". This comes from ambari and I can remove from hive-site.xml, but ambari will put it back.
Everything else was as I would expect.
hive.llap.io.enabled is true.
According to Grafana, I have a 12Gb cache, but there isn't anything in it.
Thanks for your help, I appreciate it..
Created 02-21-2017 10:18 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I should also add everything looks correct, starts correctly and runs well. It just isn't using the io cache. I do have millions of these messages in yarn timeline server log, but from looking at the orc writer code it doesn't look like orc writers uses timeline server:
2017-02-21 00:20:36,581 WARN timeline.EntityGroupFSTimelineStore (LogInfo.java:doParse(207)) - Error putting entity: dag_1487651061826_0016_921 (TEZ_DAG_ID): 6
Other than that, everything is clean.
Thanks again, I appreciate it.
Created 02-21-2017 10:34 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hive.llap.io.memory.mode is in Advanced hive-interactive-site configuration tab in Ambari UI. Could you make me a favor and check that it shows in that tab?
Created 02-21-2017 11:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes - it is in advanced hive-interactive-site. Also notice, there is no set-recommended button (blue 3/4 circle arrow). Thanks again Constantin.

