Support Questions
- Cloudera Community
- Support
- Support Questions
- NIFI putHiveStreaming processor error
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
NIFI putHiveStreaming processor error
Created 03-07-2018 04:41 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
please see the attached error , i am feeding it JSON data but its complaining about AVRO format.
Created 03-08-2018 12:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Output of QueryDatabaseTable processor are always in avro format , so you need to use PutHiveStreaming processor after Querydatabasetable processor.
As PutHiveStreaming processor expects incoming data to be in avro format and we are getting incoming data from querydatabasetable in avro format.
Flow:-
1.QueryDatabasetable
2.PutHiveStreaming
3.LogAttribute
please refer to below links regarding table creation of puthivestreaming processor
https://community.hortonworks.com/questions/59411/how-to-use-puthivestreaming.html
https://community.hortonworks.com/articles/52856/stream-data-into-hive-like-a-king-using-nifi.html
Created 03-08-2018 08:41 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @Sami Ahmad,
As stated in the processor description/documentation:
This processor uses Hive Streaming to send flow file data to an Apache
Hive table. The incoming flow file is expected to be in Avro format and
the table must exist in Hive. Please see the Hive documentation for
requirements on the Hive table (format, partitions, etc.). The partition
values are extracted from the Avro record based on the names of the
partition columns as specified in the processor. NOTE: If multiple
concurrent tasks are configured for this processor, only one table can
be written to at any time by a single thread. Additional tasks intending
to write to the same table will wait for the current task to finish
writing to the table.
You'll need to convert your data into avro first. The best approach is to use the record processors for that.
Hope this helps.
Created 03-12-2018 09:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Created 03-08-2018 12:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Output of QueryDatabaseTable processor are always in avro format , so you need to use PutHiveStreaming processor after Querydatabasetable processor.
As PutHiveStreaming processor expects incoming data to be in avro format and we are getting incoming data from querydatabasetable in avro format.
Flow:-
1.QueryDatabasetable
2.PutHiveStreaming
3.LogAttribute
please refer to below links regarding table creation of puthivestreaming processor
https://community.hortonworks.com/questions/59411/how-to-use-puthivestreaming.html
https://community.hortonworks.com/articles/52856/stream-data-into-hive-like-a-king-using-nifi.html
Created 03-12-2018 09:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Shu this flow you mentioned 1) QueryDatabasetable 2)PutHiveStreaming 3)LogAttribute is not working for me , can you please take a look at the errors / the attached flow file ?
Created on 03-13-2018 12:07 AM - edited 08-18-2019 01:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sad to hear that 😞
I tried to create the same flow and it works as expected.
Here is what i tried..
i have create a table in hive bucketed,partitioned,orc format,transactional.
hive ddl:-
hive> create table default.tmp(id string,name string)
partitioned by(ts timestamp)
clustered by (id)
into 2 buckets
stored as orc
TBLPROPERTIES ("transactional"="true");hive> desc tmp; +--------------------------+-----------------------+-----------------------+--+ | col_name | data_type | comment | +--------------------------+-----------------------+-----------------------+--+ | id | string | | | name | string | | | ts | timestamp | | | | NULL | NULL | | # Partition Information | NULL | NULL | | # col_name | data_type | comment | | | NULL | NULL | | ts | timestamp | | +--------------------------+-----------------------+-----------------------+--+
i have created the tmp table with id,name columns as string types and partitioned by ts as timestamp type.
Now PutHiveStreaming Processor Configs:-

select data from tmp table now:-
hive> select * from tmp; +-----+-------+--------------------------+--+ | id | name | ts | +-----+-------+--------------------------+--+ | 1 | hdf | 2015-01-02 20:23:20.0 | | 1 | hdf | 2015-01-02 20:23:20.0 | | 1 | hdf | 2018-03-12 19:11:51.217 | | 1 | hdf | 2018-03-12 19:11:51.24 | +-----+-------+--------------------------+--+
hive> show partitions tmp; +---------------------------------+--+ | partition | +---------------------------------+--+ | ts=2015-01-02 20%3A23%3A20.0 | | ts=2018-03-12 19%3A11%3A51.217 | | ts=2018-03-12 19%3A11%3A51.24 | +---------------------------------+--+
For testing purpose use select hiveql processor with below configs:-
HiveQL Select Query
select int(1) id,string('hdf')name,timestamp(current_timestamp)ts
Output Format
Avro
Configs:-

Test Flow:-

try this flow once and make sure you are able to load using PutHiveStreaming processor into hive.once you are able to load the data into hive then try with your scenario.
If issue still exists then share your hive create table statement and 10 records of sample data so that we can recreate and help you out ASAP.
In addition if you don't want to create partitions then create table statement would be
hive> create table default.tmp(id string,name string,ts string) --with ts as timestamp type also works
clustered by (id)
into 2 buckets
stored as orc
TBLPROPERTIES ("transactional"="true");
Created 03-15-2018 08:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
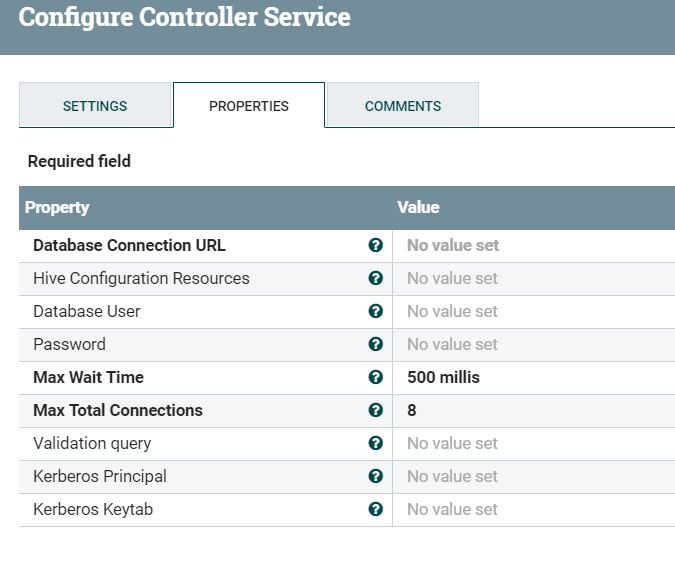
hi Shu can you please put the properties of the HiveConnectionPool ?
Created 03-15-2018 09:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This hive connection pool configs are varies depending on the setup,unfortunately there are no standard properties that i can share with you.
HiveConnectionPool configs:-
I use the below connection pool configs
Database Connection URL
jdbc:hive2://sandbox.hortonworks:2181,sandbox.hortonworks:2181,sandbox.hortonworks:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-binary;principal=hive/_HOST@HDP.LOCAL
Hive Configuration Resources
/etc/hdp/hive-site.xml,/etc/hdp/core-site.xml,/etc/hdp/hdfs-site.xml
Database User
nifi
Password No value set Max Wait Time
500 millis
Max Total Connections
8
Validation query
select current_timestamp
Please refer to below links to get your jdbc connection url and if your environment is kerberized then you need to mention kerberos principal,keytab in the connection pool service.
https://community.hortonworks.com/questions/107945/hive-database-connection-pooling-service.html
https://community.hortonworks.com/articles/4103/hiveserver2-jdbc-connection-url-examples.html
https://community.hortonworks.com/questions/64609/cannot-create-hive-connection-pool.html
Created on 03-20-2018 11:09 PM - edited 08-18-2019 01:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You have to change the data types in your create table statement as table used by put hive streaming processor expects all the datatypes would be strings(except for timestamp..etc types).
use the below create table statement
CREATE TABLE default.purchase_acct_orc (
acct_num STRING,
pur_id STRING,
pur_det_id STRING,
product_pur_product_code STRING,
prod_amt STRING,
accttype_acct_type_code STRING,
accttype_acct_status_code STRING,
emp_emp_code STRING,
plaza_plaza_id STRING,
purstat_pur_status_code STRING)
PARTITIONED BY (pur_trans_date TIMESTAMP)
CLUSTERED BY(acct_num) INTO 5 BUCKETS
STORED AS ORC
TBLPROPERTIES ("transactional"="true");Then start the put hive streaming processor.
As i tried with same create table statement as above and the data that you have provided in the comment and i'm able to load the data into the table.
Flow:-

Select Hive Ql configs:-

HiveQL Select Query
select string(16680934) ACCT_NUM,string(747032990) PUR_ID,string(656564856) PUR_DET_ID,string(31) PRODUCT_PUR_PRODUCT_CODE,string(50) PROD_AMT,string('2015-01-01 08:12:03.0') PUR_TRANS_DATE,string(1) ACCTTYPE_ACCT_TYPE_CODE,string(01) ACCTTYPE_ACCT_STATUS_CODE,string(9999) EMP_EMP_CODE,string(009500 )PLAZA_PLAZA_ID,string(10) PURSTAT_PUR_STATUS_CODE
Output Format
Avro
Puthivestreaming Configs:-

{kind=link}
{kind=link}
Output:-
select * from default.purchase_acct_orc; +-----------+------------+-------------+---------------------------+-----------+--------------------------+----------------------------+---------------+-----------------+--------------------------+------------------------+--+ | acct_num | pur_id | pur_det_id | product_pur_product_code | prod_amt | accttype_acct_type_code | accttype_acct_status_code | emp_emp_code | plaza_plaza_id | purstat_pur_status_code | pur_trans_date | +-----------+------------+-------------+---------------------------+-----------+--------------------------+----------------------------+---------------+-----------------+--------------------------+------------------------+--+ | 16680934 | 747032990 | 656564856 | 31 | 50 | 1 | 1 | 9999 | 9500 | 10 | 2015-01-01 08:12:03.0 | +-----------+------------+-------------+---------------------------+-----------+--------------------------+----------------------------+---------------+-----------------+--------------------------+------------------------+--+
Let us know if you have any issues..!!
Created 03-21-2018 01:40 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi Shu
yes the table structure you gave fixed the issue and its loading now but something strange is happening , it got stuck on 104 for a while and I stopped the QueryDatabaseTable processor , then after a while I noticed it had dumped more records . I guess its just slow ?
how can I tune the loading app as its extremely slow.
thanks
18555604 747495984 657020052 31 25 01 NULL 9985 009500 10 2015-01-03 10:02:41 Time taken: 0.089 seconds, Fetched: 104 row(s) hive> <br>

