Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Spark HBase Connector (SHC) job fails to conne...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Spark HBase Connector (SHC) job fails to connect to Zookeeper cause connection faillure to HBase
- Labels:
-
Apache HBase
Created 01-31-2017 12:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I am trying to execute a basic code using the shc connector. It is a connector apparently provide by Hortonworks (in their github at least) that conveniently allows to insert/request data on HBase. So the code rework from the example of the project is building a Dataframe of fake data and try to insert it via the connector.
This is the hbase configuration:
screenshot-from-2017-01-31-13-47-21.png
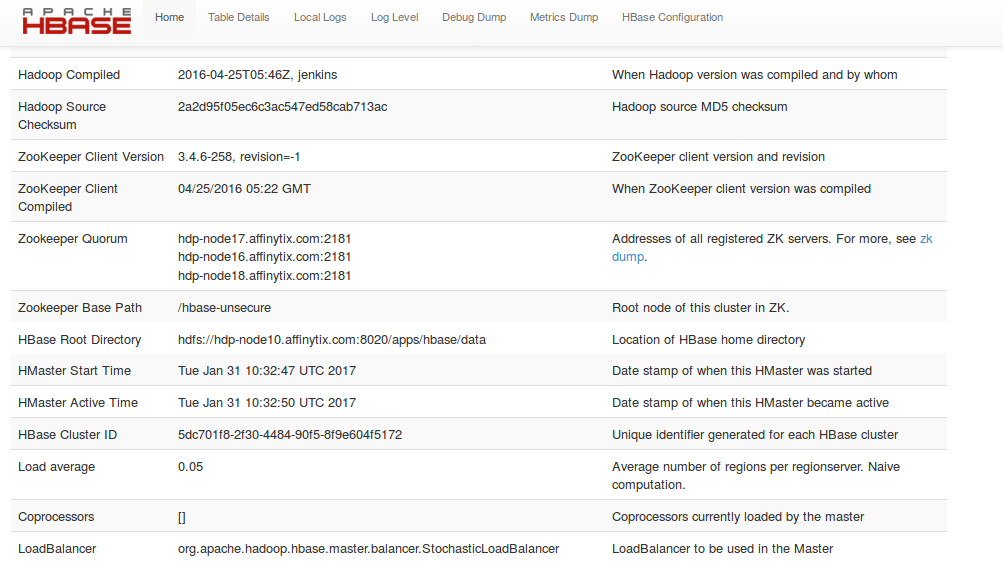{kind=link}
The code is run under a spark shell which launching command line is the following:
spark-shell --master yarn \
--deploy-mode client \
--name "hive2hbase" \
--repositories "http://repo.hortonworks.com/content/groups/public/" \
--packages "com.hortonworks:shc-core:1.0.1-1.6-s_2.10" \
--files "/usr/hdp/current/hbase-client/conf/hbase-site.xml,/usr/hdp/current/hive-client/conf/hive-site.xml" \
--jars /usr/hdp/current/phoenix-client/phoenix-server.jar
--driver-memory 1G \
--executor-memory 1500m \
--num-executors 8The log of spark shell tells me that it correctly load the hbase-site.xml and hive-site.xml files. I also checked that the configuration of the zookeeper quorum is correct in the HBase configuration. However the zookeeper objects are failing to connect because they are trying quorum:localhost:2081 instead of the addresses of the one of the three zookeeper nodes.
As a consequence it also fails to give me the HBase connection that is needed.
Note: I already tried to erase from the zookeeper command line the configuration relative to hbase (/hbase-unsecure) and restart zookeeper so as to let him rebuild it but this solution fails also.
Thanks for any help that may be provided
Created 01-31-2017 08:04 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Samuel,
Just for the sake of narrowing down the issue, can you add the hbase-site.xml, hive-site.xml to SPARK_CLASSPATH and retry ?
Created 01-31-2017 08:04 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Samuel,
Just for the sake of narrowing down the issue, can you add the hbase-site.xml, hive-site.xml to SPARK_CLASSPATH and retry ?
Created 02-01-2017 11:16 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I thought that's what I did 😉 What is the purpose of adding the files to spark-shell by --files option if it is not to add it to the spark classpath.
You said: "can you add the hbase-site.xml, hive-site.xml to SPARK_CLASSPATH and retry ?"
How do you do this ?
Note: please see the next post for hive-site.xml and hbase-site.xml
Many thanks for your answer.
Created 02-01-2017 10:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--files will add it to the working directory of the YARN app master and container and this would mean that those files (and not jars) would be in the classpath of the app master and container. But in client mode jobs the main driver code is running in the client machine. So these --files are not available on the driver. SPARK_CLASSPATH adds these files to the driver classpath. Its an env var. So one could say the following. Note it will warn saying its deprecated and cannot be used concurrently with --driver-class-path option. More information can be found here.
https://github.com/hortonworks-spark/shc
export SPARK_CLASSPATH=/a/b/c/hbase-site.xml;/d/e/f/hive-site.xml
Created 02-07-2017 12:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your advice it seems this is the problem.
As a test I ran the example of the shc connector here with --master yarn-cluster and --master yarn-client and this was the problem. The quorum are respectively found/not found in each test. So spark doest not have the file in its path when working as a client.
Created 01-31-2017 08:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The error you are getting is this
Unable to set watcher on znode (/hbase/hbaseid)
Is your zookeeper running? If yes, please share your hbase-site.xml.
Created 02-01-2017 11:22 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My zookeeper is running green on the ambari. I am able to hbase shell from the node where I launch the spark-shell.
No problem. Here it is:
Created 02-01-2017 11:10 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
what is this script element in your hbase-site.xml and hive-site.xml. Can you please remove that and try it again?
Created 02-02-2017 06:01 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't see no script element in these files. What do you mean ?
Created 02-02-2017 08:09 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see following in your hbase-site.xml when I open it.
<script data-x-lastpass="">
(function(){var c=0;if("undefined"!==typeof CustomEvent&&"function"===typeof window.dispatchEvent){var a=function(a){try{if("object"===typeof a&&(a=JSON.stringify(a)),"string"===typeof a)return window.dispatchEvent(new CustomEvent("lprequeststart",{detail:{data:a,requestID:++c}})),c}catch(f){}},b=function(a){try{window.dispatchEvent(new CustomEvent("lprequestend",{detail:a}))}catch(f){}};"undefined"!==typeof XMLHttpRequest&&XMLHttpRequest.prototype&&XMLHttpRequest.prototype.send&&(XMLHttpRequest.prototype.send= function(c){return function(f){var d=this,e=a(f);e&&d.addEventListener("loadend",function(){b({requestID:e,statusCode:d.status})});return c.apply(d,arguments)}}(XMLHttpRequest.prototype.send));"function"===typeof fetch&&(fetch=function(c){return function(f,d){var e=a(d),g=c.apply(this,arguments);if(e){var h=function(a){b({requestID:e,statusCode:a&&a.status})};g.then(h)["catch"](h)}return g}}(fetch))}})(); (function(){if("undefined"!==typeof CustomEvent){var c=function(a){if(a.lpsubmit)return a;var b=function(){try{this.dispatchEvent(new CustomEvent("lpsubmit"))}catch(k){}return a.apply(this,arguments)};b.lpsubmit=!0;return b};window.addEventListener("DOMContentLoaded",function(){if(document&&document.forms&&0<document.forms.length)for(var a=0;a<document.forms.length;++a)document.forms[a].submit=c(document.forms[a].submit)},!0);document.createElement=function(a){return function(){var b=a.apply(this, arguments);b&&"FORM"===b.nodeName&&b.submit&&(b.submit=c(b.submit));return b}}(document.createElement)}})();
</script>

