Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Spark HBase Connector (SHC) job fails to conne...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Spark HBase Connector (SHC) job fails to connect to Zookeeper cause connection faillure to HBase
- Labels:
-
Apache HBase
Created 01-31-2017 12:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I am trying to execute a basic code using the shc connector. It is a connector apparently provide by Hortonworks (in their github at least) that conveniently allows to insert/request data on HBase. So the code rework from the example of the project is building a Dataframe of fake data and try to insert it via the connector.
This is the hbase configuration:
screenshot-from-2017-01-31-13-47-21.png
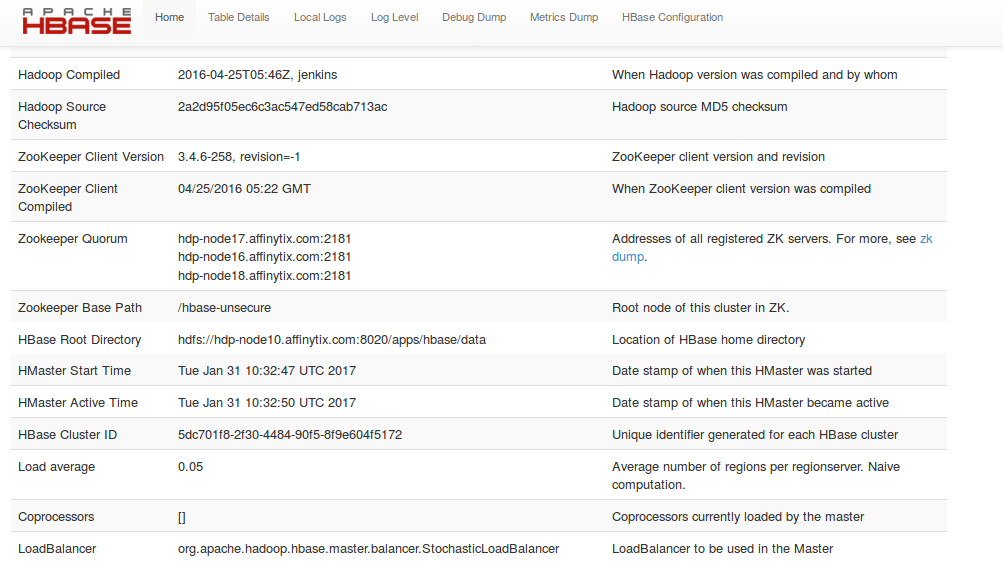{kind=link}
The code is run under a spark shell which launching command line is the following:
spark-shell --master yarn \
--deploy-mode client \
--name "hive2hbase" \
--repositories "http://repo.hortonworks.com/content/groups/public/" \
--packages "com.hortonworks:shc-core:1.0.1-1.6-s_2.10" \
--files "/usr/hdp/current/hbase-client/conf/hbase-site.xml,/usr/hdp/current/hive-client/conf/hive-site.xml" \
--jars /usr/hdp/current/phoenix-client/phoenix-server.jar
--driver-memory 1G \
--executor-memory 1500m \
--num-executors 8The log of spark shell tells me that it correctly load the hbase-site.xml and hive-site.xml files. I also checked that the configuration of the zookeeper quorum is correct in the HBase configuration. However the zookeeper objects are failing to connect because they are trying quorum:localhost:2081 instead of the addresses of the one of the three zookeeper nodes.
As a consequence it also fails to give me the HBase connection that is needed.
Note: I already tried to erase from the zookeeper command line the configuration relative to hbase (/hbase-unsecure) and restart zookeeper so as to let him rebuild it but this solution fails also.
Thanks for any help that may be provided
Created 01-31-2017 08:04 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Samuel,
Just for the sake of narrowing down the issue, can you add the hbase-site.xml, hive-site.xml to SPARK_CLASSPATH and retry ?
Created 02-02-2017 08:06 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Samuel,
Have you tried by explicitly exporting the hbase-site.xml to SPARK_CLASSPATH ?
Your logs show that the hbase base znode is /hbase, whereas the hbase-site.xml shows that the base znode is /hbase-unsecure. This indicates that spark hbase connector is not looking at the correct hbase-site.xml.
Created 02-05-2017 01:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am going to do it. I had production problem until now that kept me out of the problem. It is not close and I will try with your advice. Thanks.
Created 02-07-2017 12:00 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your advice it seems this is the problem.
As a test I ran the example of the shc connector here with --master yarn-cluster and --master yarn-client and this was the problem. The quorum are respectively found/not found in each test. So spark doest not have the file in its path when working as a client.
Created 02-06-2017 02:32 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Samuel,
You probably need to copy hbase-site.xml to /etc/spark/conf folder.
Created 02-07-2017 11:56 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No this is absolutely not the problem. It does not guarantee in any manner that the spark job will take it into account. See answer to @anatva for a proper answer to this.
Further more my post indicate that --files option is used with the correct files passed.
Created 09-21-2018 02:53 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is the code
ubuntu@ip-10-0-2-24:~$ spark-shell --packages com.hortonworks:shc-core:1.1.0-2.1 -s_2.11 --repositories http://repo.hortonworks.com/content/groups/public/ scala> import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.{SQLContext, _}
scala> import org.apache.spark.sql.execution.datasources.hbase._
import org.apache.spark.sql.execution.datasources.hbase._
scala> import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.{SparkConf, SparkContext}
scala> import spark.sqlContext.implicits._
import spark.sqlContext.implicits._
scala> def catalog = s"""{ | |"table":{"namespace":"default", "name":"Contacts"}, | |"rowkey":"key", | |"columns":{ | |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, | |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, | |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, | |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, | |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} | |} | |}""".stripMargin catalog: String
scala> def withCatalog(cat: String): DataFrame = { | spark.sqlContext | .read | .options(Map(HBaseTableCatalog.tableCatalog->cat)) | .format("org.apache.spark.sql.execution.datasources.hbase") | .load() | }
withCatalog: (cat: String)org.apache.spark.sql.DataFrame
scala> val df = withCatalog(catalog) df: org.apache.spark.sql.DataFrame = [rowkey: string, officeAddress: string ... 3 more fields]
this is the error
scala> df.show
java.lang.RuntimeException: java.lang.NullPointerException at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:208) at org.apache.hadoop.hbase.client.ClientScanner.call(ClientScanner.java:320) at org.apache.hadoop.hbase.client.ClientScanner.nextScanner(ClientScanner.java:295) at org.apache.hadoop.hbase.client.ClientScanner.initializeScannerInConstruction(ClientScanner.java:160) at org.apache.hadoop.hbase.client.ClientScanner.<init>(ClientScanner.java:155) at org.apache.hadoop.hbase.client.HTable.getScanner(HTable.java:821) at org.apache.hadoop.hbase.client.MetaScanner.metaScan(MetaScanner.java:193) at org.apache.hadoop.hbase.client.MetaScanner.metaScan(MetaScanner.java:89) at org.apache.hadoop.hbase.client.MetaScanner.listTableRegionLocations(MetaScanner.java:343) at org.apache.hadoop.hbase.client.HRegionLocator.listRegionLocations(HRegionLocator.java:142) at org.apache.hadoop.hbase.client.HRegionLocator.getStartEndKeys(HRegionLocator.java:118) at org.apache.spark.sql.execution.datasources.hbase.RegionResource$anonfun$1.apply(HBaseResources.scala:109) at org.apache.spark.sql.execution.datasources.hbase.RegionResource$anonfun$1.apply(HBaseResources.scala:108) at org.apache.spark.sql.execution.datasources.hbase.ReferencedResource$class.releaseOnException(HBaseResources.scala:77) at org.apache.spark.sql.execution.datasources.hbase.RegionResource.releaseOnException(HBaseResources.scala:88) at org.apache.spark.sql.execution.datasources.hbase.RegionResource.<init>(HBaseResources.scala:108) at org.apache.spark.sql.execution.datasources.hbase.HBaseTableScanRDD.getPartitions(HBaseTableScan.scala:61) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:252) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:250) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:250) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:252) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:250) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:250) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:252) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:250) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:250) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:252) at org.apache.spark.rdd.RDD$anonfun$partitions$2.apply(RDD.scala:250) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:250) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:314) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:38) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$collectFromPlan(Dataset.scala:2861) at org.apache.spark.sql.Dataset$anonfun$head$1.apply(Dataset.scala:2150) at org.apache.spark.sql.Dataset$anonfun$head$1.apply(Dataset.scala:2150) at org.apache.spark.sql.Dataset$anonfun$55.apply(Dataset.scala:2842) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:2841) at org.apache.spark.sql.Dataset.head(Dataset.scala:2150) at org.apache.spark.sql.Dataset.take(Dataset.scala:2363) at org.apache.spark.sql.Dataset.showString(Dataset.scala:241) at org.apache.spark.sql.Dataset.show(Dataset.scala:637) at org.apache.spark.sql.Dataset.show(Dataset.scala:596) at org.apache.spark.sql.Dataset.show(Dataset.scala:605) ... 54 elided Caused by: java.lang.NullPointerException at org.apache.hadoop.hbase.zookeeper.ZooKeeperWatcher.getMetaReplicaNodes(ZooKeeperWatcher.java:395) at org.apache.hadoop.hbase.zookeeper.MetaTableLocator.blockUntilAvailable(MetaTableLocator.java:553) at org.apache.hadoop.hbase.client.ZooKeeperRegistry.getMetaRegionLocation(ZooKeeperRegistry.java:61) at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.locateMeta(ConnectionManager.java:1185) at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.locateRegion(ConnectionManager.java:1152) at org.apache.hadoop.hbase.client.RpcRetryingCallerWithReadReplicas.getRegionLocations(RpcRetryingCallerWithReadReplicas.java:300) at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:151) at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:59) at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:200) ... 103 more
- « Previous
-
- 1
- 2
- Next »

