Archives of Support Questions (Read Only)
- Cloudera Community
- Board Archive
- Archives of Support Questions (Read Only)
- hdfs data disk size is exceeding 90% threshold whi...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
hdfs data disk size is exceeding 90% threshold while rest of the disks(in the same server) are about 55%
- Labels:
-
Apache Hadoop
Created 12-04-2016 04:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
Can you please guide me how to troubleshoot why one of the disks in one data node is exceeding its size than the others.
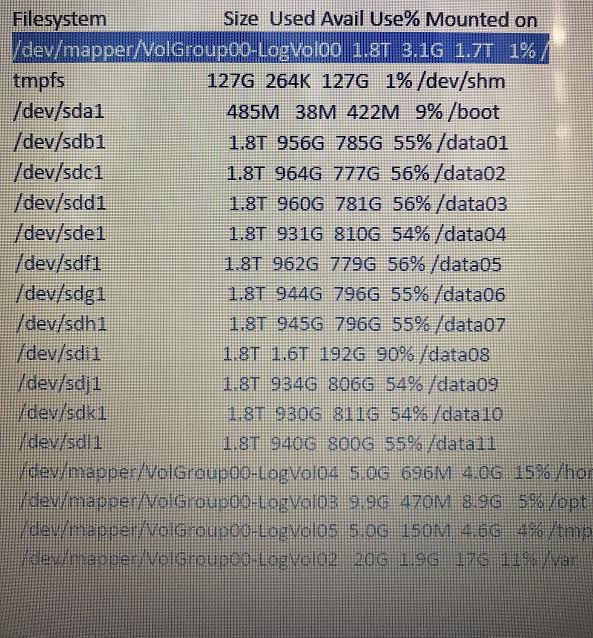
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00 1.8T 3.1G 1.7T 1% / tmpfs 127G 264K 127G 1% /dev/shm /dev/sda1 485M 38M 422M 9% /boot /dev/sdb1 1.8T 956G 785G 55% /data01 /dev/sdc1 1.8T 964G 777G 56% /data02 /dev/sdd1 1.8T 960G 781G 56% /data03 /dev/sde1 1.8T 931G 810G 54% /data04 /dev/sdf1 1.8T 962G 779G 56% /data05 /dev/sdg1 1.8T 944G 796G 55% /data06 /dev/sdh1 1.8T 945G 796G 55% /data07 /dev/sdi1 1.8T 1.6T 192G 90% /data08 /dev/sdj1 1.8T 934G 806G 54% /data09 /dev/sdk1 1.8T 930G 811G 54% /data10 /dev/sdl1 1.8T 940G 800G 55% /data11 /dev/mapper/VolGroup00-LogVol04 5.0G 696M 4.0G 15% /home /dev/mapper/VolGroup00-LogVol03 9.9G 470M 8.9G 5% /opt /dev/mapper/VolGroup00-LogVol05 5.0G 150M 4.6G 4% /tmp /dev/mapper/VolGroup00-LogVol02 20G 1.9G 17G 11% /var
Created 12-05-2016 05:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@PJ Depending on your situation there are many solutions.
This was a fundamental issue in HDFS for a long time. Very recently we have fixed this issue, there is a new tool called DiskBalancer -- which ships with trunk. If you want to see the details of the design and fix -- please look at https://issues.apache.org/jira/browse/HDFS-1312 .
It essentially allows you to create a plan file -- That describes how data will be moved from disk to disk and then you can ask a datanode to execute it.
Unfortunately, this tool is yet to be shipped as part of HDP. Soon we will be shipping it.
Presuming you are running an older version of HDFS, and you have many datanodes in the cluster, you can decommission this full node and re-add them. However the speed of HDFS replication is throttled, so if you want this to happen fast, you might have to set these parameters in your cluster.
- dfs.namenode.replication.work.multiplier.per.iteration = 10
- dfs.namenode.replication.max-streams = 50
- dfs.namenode.replication.max-streams-hard-limit = 100
Last, the one that I would least advise you to do, I am writing this down for the sake of completeness, is to follow what the apache documentation suggests.
Please note, this is a dangerous action and unless you really know what you are doing this can lead to data loss. So please, please make sure that you can restore the machine to earlier state if you really decide to go this route.
Created 12-04-2016 04:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here i am talking about data08 disk
Created 12-04-2016 04:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
Created 12-04-2016 08:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Same exact thing happened on another datanode ... Can somebody please help me with the cause and solutions...
Created 12-04-2016 09:40 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try rebalancing the blocks across DataNodes in your cluster. HDFS data is not always placed uniformly across the DataNodes.
Here is a link to the manual on how to rebalance:
Created 12-04-2016 10:34 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Binu,
Thanks so much for your reply. But rebalancing is done among Datanodes, I dont think it will balance the disks within the datanode. Do you think it will still work or any other solution?
Created 12-05-2016 01:51 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The balancer does not balance between individual disks on a single data node. Assuming Data nodes are fairly balanced across the cluster, why do you care? If you have multiple nodes and this one disk is reaching capacity, that shouldn't affect how Hadoop works. As new data comes in, Hadoop will be smart enough to place blocks on other nodes.
Now, a question that comes to mind is, do you have other things on this disk (I mean other than HDFS data)? Can you do a cat /proc/mount to check what is mounted on your /dev/sdi? There might be other things that are taking space.
Created 12-05-2016 03:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I assumed you were referring to HDFS disk usage. What happens when you run 'hdfs dfsadmin -report'
Are you seeing uneven distribution of blocks? If so, then rebalancing via Ambari will help with uniform distribution of your HDFS data
Created 12-05-2016 02:58 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Qureshi,
Here is the output for cat /proc/mounts
[root@str14 ~]# cat /proc/mounts rootfs / rootfs rw 0 0 proc /proc proc rw,relatime 0 0 sysfs /sys sysfs rw,relatime 0 0 devtmpfs /dev devtmpfs rw,relatime,size=132217636k,nr_inodes=33054409,mode=755 0 0 devpts /dev/pts devpts rw,relatime,gid=5,mode=620,ptmxmode=000 0 0 tmpfs /dev/shm tmpfs rw,relatime 0 0 /dev/mapper/VolGroup00-LogVol00 / ext4 rw,noatime,nodiratime,barrier=1,data=ordered 0 0 /proc/bus/usb /proc/bus/usb usbfs rw,relatime 0 0 /dev/sda1 /boot ext4 rw,relatime,barrier=1,data=ordered 0 0 /dev/sdb1 /data01 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdc1 /data02 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdd1 /data03 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sde1 /data04 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdf1 /data05 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdg1 /data06 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdh1 /data07 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdi1 /data08 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdj1 /data09 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdk1 /data10 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/sdl1 /data11 ext4 rw,noatime,nodiratime,commit=60,barrier=1,nobh,data=writeback 0 0 /dev/mapper/VolGroup00-LogVol04 /home ext4 rw,noatime,nodiratime,barrier=1,data=ordered 0 0 /dev/mapper/VolGroup00-LogVol03 /opt ext4 rw,noatime,nodiratime,barrier=1,data=ordered 0 0 /dev/mapper/VolGroup00-LogVol05 /tmp ext4 rw,noatime,nodiratime,barrier=1,data=ordered 0 0 /dev/mapper/VolGroup00-LogVol02 /var ext4 rw,noatime,nodiratime,barrier=1,data=ordered 0 0 none /proc/sys/fs/binfmt_misc binfmt_misc rw,relatime 0 0 sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw,relatime 0 0 nfsd /proc/fs/nfsd nfsd rw,relatime 0 0
Created 12-05-2016 05:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@PJ Depending on your situation there are many solutions.
This was a fundamental issue in HDFS for a long time. Very recently we have fixed this issue, there is a new tool called DiskBalancer -- which ships with trunk. If you want to see the details of the design and fix -- please look at https://issues.apache.org/jira/browse/HDFS-1312 .
It essentially allows you to create a plan file -- That describes how data will be moved from disk to disk and then you can ask a datanode to execute it.
Unfortunately, this tool is yet to be shipped as part of HDP. Soon we will be shipping it.
Presuming you are running an older version of HDFS, and you have many datanodes in the cluster, you can decommission this full node and re-add them. However the speed of HDFS replication is throttled, so if you want this to happen fast, you might have to set these parameters in your cluster.
- dfs.namenode.replication.work.multiplier.per.iteration = 10
- dfs.namenode.replication.max-streams = 50
- dfs.namenode.replication.max-streams-hard-limit = 100
Last, the one that I would least advise you to do, I am writing this down for the sake of completeness, is to follow what the apache documentation suggests.
Please note, this is a dangerous action and unless you really know what you are doing this can lead to data loss. So please, please make sure that you can restore the machine to earlier state if you really decide to go this route.

