Archives of Support Questions (Read Only)
- Cloudera Community
- Board Archive
- Archives of Support Questions (Read Only)
- hive table loading in NIFI extremely slow
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
hive table loading in NIFI extremely slow
Created 03-22-2018 03:06 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hive-nifi-load.xmlif I load the hive table via sqoop the loading is extremely fast compared to if I load it via Nifi.
with Nifi its loading only 100 records / 30 mins
how can I make NIFI table loading faster ? I am attaching the nifi flow file.
the table ddl is as follows :
CREATE TABLE default.purchase_acct_orc (
acct_num STRING,
pur_id STRING,
pur_det_id STRING,
product_pur_product_code STRING,
prod_amt STRING,
accttype_acct_type_code STRING,
accttype_acct_status_code STRING,
emp_emp_code STRING,
plaza_plaza_id STRING,
purstat_pur_status_code STRING)
PARTITIONED BY (pur_trans_date TIMESTAMP)
CLUSTERED BY(acct_num) INTO 5 BUCKETS
STORED AS ORC
TBLPROPERTIES
("transactional"="true");
thanks
Created 03-22-2018 03:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you are using NiFi 1.2+ then the below link help you to speed up the process,
(or)
if you are running Querydatabase table processor more often(0 sec,1 sec..<15 mins) then we are going to end up with lot of smaller files in hdfs directory.
in this case it's better to use merge content processor with merge format as avro after query database table and merge the small files into one big file keep age off duration to flush out the merged files after certain amount of time
Merge content configs reference:-
Hive to do the conversion from Avro to ORC:-
You can store into tmp location(as avro format) once you pull the data by using PutHDFS after Querydatabase table processor and use puthiveql processor to get the data from temp location to insert into final location(orc format).
(or)
NiFi to do the conversion from Avro to ORC:-
After Querydatabase table processor use SplitAvro Processor if you want to split into chunks of data then use ConvertAvroToOrc processor then use PutHDFS processor to store the orc files into HDFS directory. Create an external table on the HDFS directory.
Use the attached xml for reference for this method
Let us know if you are facing any issues ..!!
Created 03-22-2018 03:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you are using NiFi 1.2+ then the below link help you to speed up the process,
(or)
if you are running Querydatabase table processor more often(0 sec,1 sec..<15 mins) then we are going to end up with lot of smaller files in hdfs directory.
in this case it's better to use merge content processor with merge format as avro after query database table and merge the small files into one big file keep age off duration to flush out the merged files after certain amount of time
Merge content configs reference:-
Hive to do the conversion from Avro to ORC:-
You can store into tmp location(as avro format) once you pull the data by using PutHDFS after Querydatabase table processor and use puthiveql processor to get the data from temp location to insert into final location(orc format).
(or)
NiFi to do the conversion from Avro to ORC:-
After Querydatabase table processor use SplitAvro Processor if you want to split into chunks of data then use ConvertAvroToOrc processor then use PutHDFS processor to store the orc files into HDFS directory. Create an external table on the HDFS directory.
Use the attached xml for reference for this method
Let us know if you are facing any issues ..!!
Created 03-22-2018 07:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am using NIFI 1.2 .
If you look at the flow , its not showing any values for "in" for the PutHiveStreaming processor , why ? even though at this point I can see 29 records in the database . The inbound queue number has increased to 10 but no more records are added yet to the database . I know later it will be .
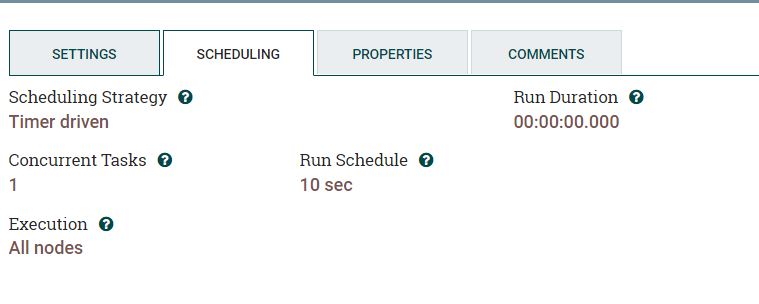
both the QuerydatabaseProcessor and the PutHiveStreaming processor schedule time is set to 30 secs.
how can you explain this behavior ? (please see attached ) capture.jpg
{kind=link}
Created 03-22-2018 08:44 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Sami Ahmad
You will notice a small number in the upper right corner of the putHiveStreaming processor. This indicates that there is an active thread in progress. "IN" shows the number of Flowfiles that were processed off an inbound connection in the last 5 minutes. A number will not be reported here until the process complete (successfully or otherwise). FlowFiles remain on the inbound connection until they have been successfully processed (This is so NiFi can recover if it is dies mid processing).
You can collect a nifi thread dump to analyze what is going on with this putHiveStreaming thread.
./nifi.sh dump <name of dumpfile>
Thanks,
Matt
Created 03-22-2018 09:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok I have this flow working where I am reading the table from the database and creating ORC file in hdfs .
its running now and I see the files are increasing . for 1000 rows table it has created so far 44 orc files .
How do I know when the process will stop ? or can I know how many files will be created for my table?
will the QueryDatabaseTable process stop once all the 1000 table rows are read ?
{kind=link}
Created 03-22-2018 11:22 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Query Database table processor stores the last state value(if we mention Maximum-value Columns) and run incrementally based on your run schedule.If no columns are provided in Maximum value columns then all rows from the table will be considered, which could have a performance impact. NOTE: It is important to use consistent max-value column names for a given table for incremental fetch to work properly.
So let's consider you have some incremental column in your source table and you have mentioned incremental column as Maximum value column in query databasetable processor.
For the first time this processor pulls all the records and updates the state (consider your last state is 2018-03-22 19:11:00), for the next run this processor only pulls the columns that have incremental column value more than stored state value i.e 2018-03-22 19:11:00. if there are no records that have new updated incremental column value then this processor won't return any flowfiles(because no records got added/updated).
for more reference about querydatabasetable
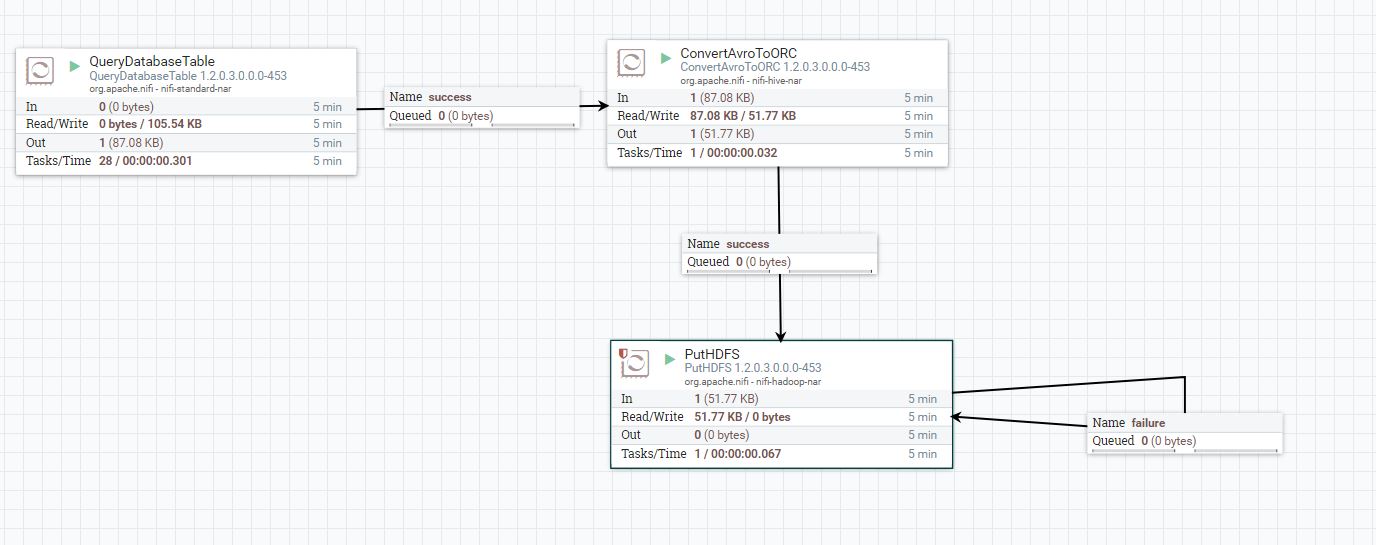
In your screenshot you have connected success and failure relationships again to puthdfs processor ,even if the flowfiles has successfully stored into hdfs then those flowfiles route to success relation and you have looped back it to same processor again which will try to keep the same file again and again if the conflict resulution strategy is set to fail then you will end up with filling logs with this error.
it's better to use retry loop for failure relation and for success relation just auto terminate (or) drag a funnel and feed success relation to funnel.
Retry loop references
There are some links which can gives insights how put hive streaming processor works
https://community.hortonworks.com/questions/84948/accelerate-working-processor-puthivestreaming.html
https://issues.apache.org/jira/browse/NIFI-3418
https://cwiki.apache.org/confluence/display/Hive/Streaming+Data+Ingest
Created 03-23-2018 03:37 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
its working now .. It brought all 1000 rows into one ORC file . I will increase the source data and see if it creates more smaller files .
thanks a lot for your help
Created 03-23-2018 02:39 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
{kind=link}
hi Shu
I did the modifications as you suggested that is I modified the PutHDFS relation to only loop back for failure and for success auto terminate . Also I added Maximum-value-columns=pur_trans_date for QueryDatabaseTable processor .
But I am doing something wrong as if I run the flow it only creates just one ORC file and then stops.
attaching the flow and processor details , please see

