Support Questions
- Cloudera Community
- Support
- Support Questions
- understanding the NIFI example project
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
understanding the NIFI example project
- Labels:
-
Apache NiFi
Created 09-01-2016 07:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The example now at
http://hortonworks.com/hadoop-tutorial/how-to-refine-and-visualize-server-log-data/
is working fully for me ,but the hortonworks site is not explaining anything on how the things are working, is there such a document available ? if not can some one please help me understand how these components work ? e.g LogGenerator , Generator FlowFile , Replace Text, Aggregate data, Send Info, Send Error , etc etc.
I have a similar task to do of parsing a log file but without understanding how this example works I wont be able to do anything.
Created 09-01-2016 07:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'd recommend you starting bu reading the documentation about the philosophy behind NiFi as well as the documentation of each processor you are mentioning. This will explain you the concept of flow files, repository, flows, content vs attributes, etc.
Created 09-01-2016 07:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
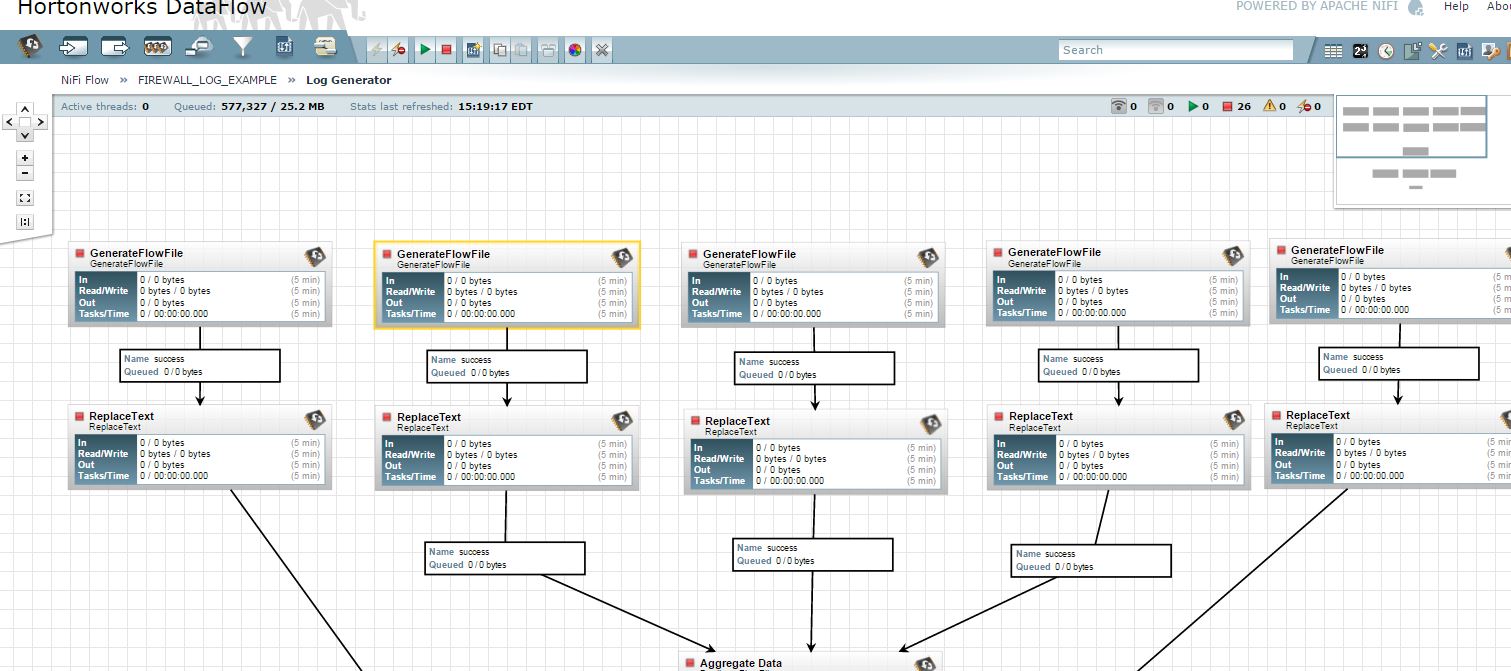
for example if I go inside LogGenerator I see 5 processors "GenerateFlowFile" , each one with exact same settings . why do we have these 5? with each one a "ReplaceText" processor is attached.
Created 09-01-2016 07:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Created 09-01-2016 07:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'd recommend you starting bu reading the documentation about the philosophy behind NiFi as well as the documentation of each processor you are mentioning. This will explain you the concept of flow files, repository, flows, content vs attributes, etc.
Created 09-01-2016 08:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi Pierre
I am reading these documents but I am still not understanding why use 5 identical processors
Created 09-01-2016 08:45 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
GenerateFlowFile processor (document is saying) generates files with random data, but no where in the processor configuration are the fields mentioned , so where do we tell or how do we know what fields this file has ?
since the ReplaceText text connector is connected to GenerateFlowFile and has to know which fields to modify right?
Created 09-01-2016 08:53 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Flow files are made of 'attributes' and 'content'. GenerateFF generates random flow files with content (or not if you don't want to). This is generally used to generate data to make start your flow but also mainly used for demonstration and test purpose. The ReplaceText processor only replaces content and is not modifying the attributes. Why five processors, simply to have generated the different part of the simulated logs you want to process. Just have a look at the configuration of each processor.
You can also start a processor but not starting the next one in the flow. This will queue up flow files in the relationship. By right clicking on the relation, then lgoing to list, you will be able to see properties of each flow files as well as content. I'm sure this will help you understand the why and how.
Created 09-01-2016 09:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
hi Pierre
attributes as I understand are key value pairs right ? so what keys does the GenerateFF generate?
I looked at the configuration of the five processors and they look exactly same .whats the difference?
Created on 09-01-2016 09:52 PM - edited 08-19-2019 02:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Correct.
As I said you can see what is generated by starting a processor to have flow file generated but not consumed by the next processor.

Then list queue

Then click on the Info button to have information displayed about the flow file:

{kind=link}
And you can even see the content of the flow file or download it.
The GenerateFF only generates what we call core attributes such as UUI (to uniquely identify a flow file), filename, path, etc.
Regarding the ReplaceText processors, this is not true, here are the configurations:
${now()}|17${now():toNumber():mod(9):toString()}.1.${now():toNumber():mod(25):toString()}.${now():toNumber():mod(255):toString()}|DE|${nextInt():mod(2):toString()}${now()}|17${now():toNumber():mod(9):toString()}.1.${now():toNumber():mod(25):toString()}.${now():toNumber():mod(255):toString()}|ITA|${nextInt():mod(2):toString()}${now()}|17${now():toNumber():mod(9):toString()}.1.${now():toNumber():mod(25):toString()}.${now():toNumber():mod(255):toString()}|USA|${nextInt():mod(2):toString()}${now()}|17${now():toNumber():mod(9):toString()}.1.${now():toNumber():mod(25):toString()}.${now():toNumber():mod(255):toString()}|IND|${nextInt():mod(2):toString()}${now()}|17${now():toNumber():mod(9):toString()}.1.${now():toNumber():mod(25):toString()}.${now():toNumber():mod(255):toString()}|FR|${nextInt():mod(2):toString()}For the purpose of the tutorial we want to generate random logs from different countries, hence the multiple processors.
Created 09-02-2016 02:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Pierre now its beginning to make some sense , so the 5 GenerateFF processors are there to take care of the 5 countries I guess.
I want to read my own log file , which processor would I use? I want to start with a simple task as read my log file , parse out some values by using the Regexp language and then save the parsed values to HIVE.

