Community Articles
- Cloudera Community
- Support
- Community Articles
- Stream data into HIVE like a Boss using NiFi HiveS...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Created on 08-23-2016 09:51 AM - edited 08-17-2019 10:40 AM

Introduction
Apache NiFi 1.0 was recently released and being integrated into Hortonworks Data Flow (HDF) that will be release very soon.
In this easy tutorial we will see how we can stream data from CSV format into Hive tables directly and start working on it right away without a single line of coding to set up the streaming.
Pre-requisites
In order to run this tutorial successfully you need to download the Following:
NiFi 1.0 or higher, you can download it from here
HDP Sandbox 2.4 or higher, you can download it from here
Download the Olympics CSV data from the attachment list below.
Changing NiFi Port (Optional)
Since Ambari and NiFi both uses port 8080, you will have problems starting NiFi if you are running the sandbox and NiFi on the same machine.
Once NiFi is downloaded, uncompress it and go to /nifi/conf/nifi.properties and change the port no to 8089 as follows:
nifi.web.http.port=8089
Starting NiFi and the Sandbox
Once NiFi is downloaded, uncompress and start it using the command:
/nifi/bin/nifi.sh start
you may open a new browser page and go to http://localhost:8089/nifi to make sure NiFi is running fine, give it a minute to load.
start the Sandbox from Vmware or Virtual Box and go to Ambari on https://localhost:8080 and make sure Hive is started.
now we lets work on the table and the streaming part…
Creating The Hive Table
Since we will have to create an empty external table, we need to make sure that the folder do exist for this table so we can store the data there without a problem, in order to do this connect to the sandbox and create the directory using the hive user:
Hive-user>hadoop fs -mkdir /user/hive/olympics
Now lets move on the the table creation,
From the downloaded olympics data olympics.zip lets examine the header of any of the file
City,Edition,Sport,sub_sport,Athlete,country,Gender,Event,Event_gender,Medal
In order for Hive Streaming to work the following has to be in place:
- Table is stored as ORC
- Transactional Property is set to “True”
- The Table is Bucketed
We will have to create a table in Hive to match the schema as following:
CREATE EXTERNAL TABLE
OLYMPICS(CITY STRING,EDITION INT,SPORT STRING,SUB_SPORT STRING,ATHLETE STRING,COUNTRY STRING,GENDER STRING,EVENT STRING,EVENT_GENDER STRING,MEDAL STRING)
CLUSTERED BY (EDITION)INTO 3 BUCKETS
ROW FORMAT DELIMITED
STORED AS ORC
LOCATION '/user/hive/olympics'
TBLPROPERTIES('transactional'='true');Once the table is created successfully we may move on to the NiFi part.
NiFi Template (Optional, if you are feeling lazy)
if you dont want to follow the steps below, you can easily download the template that contains the whole thing from here hive-streaming-olympics.xml (easily start NiFi and import it)
if you have done the previous part, just make sure to change the directories in the processors and the parameters in every processor to match your configuration.
Configure NiFi
in a high level, we need to create the following flow for our streaming to work:
- GetFile Processor to read the data directly from the source folder
- InferAvroSchema to pre-configure how the file will look like and to set any custom headers if needed.
- ConvertCSVtoAvro is where the actual conversion is happening and then forwarded to HiveStreaming
- HiveStreaming is where the data is being inserted into Hive
- We are optionally using PutFile to capture any un-successful CSVs during the streaming

For more on the Avro Conversion, refer to the great write up from @Jeremy Dyer on how to convert CSV to Avro, as it explains in greated details how the flow is working.
Pulling Data from CSV
Simply the only thing you need to do here is configure your source directory, there are some handy parameters to check based on the no. of CSV files like Batch Size(How Many CSVs per pull)

Pre-Configure the Files for Avro Conversion
Make sure Flowfile-attribute is selected for Schema Output Destination as we will capture the flow file in the next processor, Content type could be JSON or CSV in our case it will be CSV.
Since all CSVs here have no header, we will have to set teh definition for the header file easily using the processor, the header definitions will be as follow:
City,Edition,Sport,sub_sport,Athlete,country,Gender,Event,Event_gender,Medal
if we did have a header in every file, we can easily set Get CSV Header definition from Data to “true” and let NiFi determine the schema (make sure you skip a line on the next processor if you are doing that, otherwise you will have the headers ingested as well) .
CSV Header Skip Count is important if you have a custom header and you want to ignore whatever headers you previously have in your CSVs.

Convert to Avro.
Nothing much to do here except for capturing the flow file generated by the previous processor using the ${inferred.avro.schema} parameter, we dont have to skip any headers lines here as we dont have any contained within the CSVs.

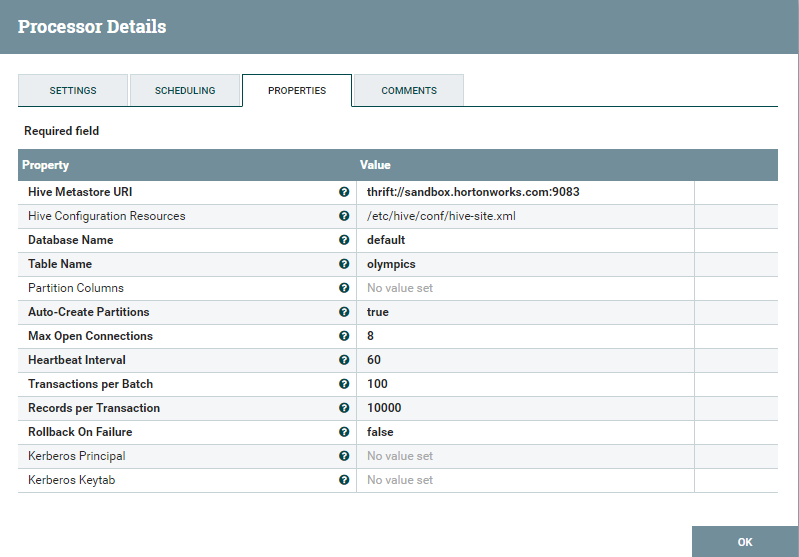
Stream into Hive
Here is where all the action is happening, you will need to configure the Hive Metastore URI to reflect the address to the sandbox (I have added sandbox.horotnworks.com in my /etc/hosts file so I don’t have to write the IP address)
Another important thing is to grab the hive-site.xml file from your sandbox (usually under /etc/hive/2.x.x.x-xxx/0/hive-site.xml), save it in a local directory and refer to it here.
Table Name will be “Olympics” where all data will be stored.

Catching any errors
In real life cases, not all CSVs are good to go, we will get some corrupted ones from now to then, configuring a processor to store those files so you can deal with them later is always a good idea, just simply add the directory on where the corrupt or faulty files will be stored.

Start Streaming
Now Simply press the play button and enjoy watching the files being streamed into Hive, watch for any red flags on the processors which means there are some sisues to resovle.
Check The Data
Once the data is streamed, you can check the data out using Ambari Hive View or even Zeppelin to visualise it.
Lets look how the data will look like in the table using the Ambari / Hive View

Now, lets do some cooler stuff with NiFi




Created on 11-23-2016 02:30 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Great article!
I needed to do the following to get this to work fully:
InferAvroSchema processor:
- City,Edition,Sport,sub_sport,Athlete,country,Gender,Event,Event_gender,Medal - produced nulls in the Hive table for columns in caps
- I made them all lower case and got the values in the Hive table
Created on 11-23-2016 06:55 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Well done Ned!
Created on 11-24-2016 04:27 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
please suggest if HIVE needs to be started with ACID and compactor on? or any other property. Thanks.
While creating the table got this error, on HDP2.5
java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:default.OLYMPICS cannot be declared transactional because it's an external table)
Also got errors with the inferred AVRO schema
How does Infer schema works in the flow, does it keep inferring for every 10 records, is that a good approach? shoudn't we use convertCSVToAVRO by providing a avsc file created by Kite. Thanks.
Created on 06-07-2017 11:01 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Ned, This is a great example over NiFi data flow. I have faced below issue while testing the same usecase:
I did install Nifi-1.2.0 as a standalone application in HDP 2.6.0. While, testing the above example, I was getting 'Failed connecting to EndPoint {metaStoreUri='thrift//sandbox.hortonworks.com:9083',database='default',table='olympics',partitionVals=[]}
Attached were the error snapshot and process details.
Please do help in getting this issue resolved. I suspect is there any compatibility issue with HDP and NiFi version which I am using currently.
Thanks in advance.
Created on 01-25-2018 03:25 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
how can you set transactional'='true' for external table in hive? I dont think its possible.
Created on 05-03-2018 09:31 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for the nice explanation Ned.
When I have created the flow, NiFi processor is able to store data to the table but its very slow in the cluster environment.
I am able to push only 2-3 flowfile/records (few kb in size) per second. I tried with more thread counts as well, but no luck.
Any suggestion will be much appreciated.
Created on 05-03-2018 09:33 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yes, its possible.
Alter table <table_name> set tblproperties ('transactional'='true');
Created on 08-21-2018 03:11 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi, Nice article.. ORC Table created, but the flow was configured for Avro.. I'm little confused here.
Created on 04-15-2019 04:51 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Even if its possible, doesn't makes sense to make an external table, transactional. External Table reads data from HDFS and making it transactional would mean the file in the HDFS will be written again and again which violates the Hadoop "write once and read many times" paradigm and also increases the write-head time on the cluster. That is why HIVE explicitly warns about this and doesn't allow you to do this.
Created on 09-03-2019 01:28 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hi @nshawa,
I am having the following error on PutHiveStreaming processor after running the template you provided:

{kind=link}
{kind=link}
Any idea how to fix this?

| User | Count |
|---|---|
| 6 | |
| 4 | |
| 2 | |
| 1 | |
| 1 |
