Support Questions
- Cloudera Community
- Support
- Support Questions
- Apache Nifi - Federated Search
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Apache Nifi - Federated Search
- Labels:
-
Apache NiFi
Created 08-16-2018 03:03 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi there!
I’ve just heard about Apache Nifi through word of mouth and wondering if somebody could point me in the right direction with my use case - my team’s recently been thrown into the deep end with some requirements and would really appreciate the help.
Problem:
Our end game is to build a federated search of customers over a variety of large separate datasets which hold varying degrees of differing data about individuals, so it’s primarily an entity resolution problem.
I was thinking Nifi could help query our various databases, merge the result, deduplicate the entries via an external tool and then push this result to an Elasticsearch instance for our applications querying.
Roughly speaking something like this (haven’t tried implementing this flow yet!):-
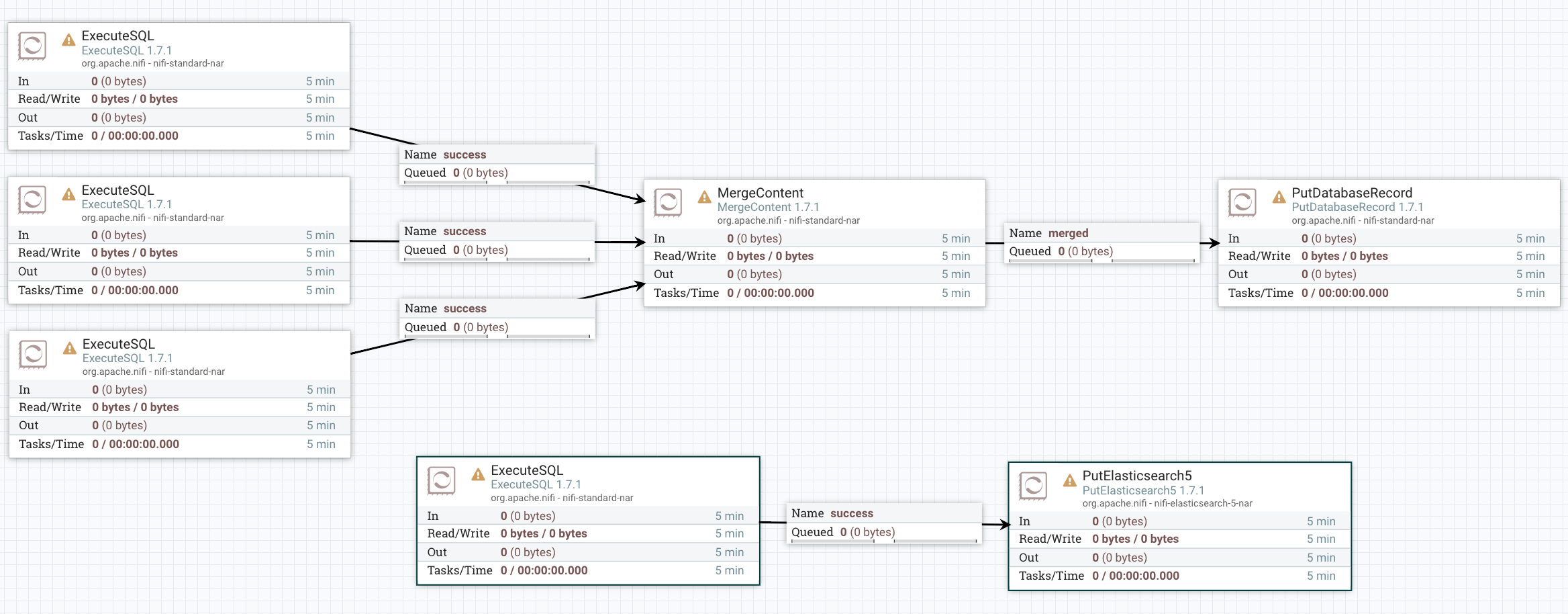{kind=link}
So, for examples sake the following data in the result database from the first flow :-
{kind=link}
Then run https://github.com/dedupeio/dedupe over this database table which will add cluster ids to aid the record linkage, e.g.:-
{kind=link}
Second flow would then feed this result into Elasticsearch instance for use by the API and front-end querying.
Questions:
- Does this approach sound feasible?
- How would I trigger dedupe to run to ultimately cluster the duplicates after the merged content was pushed to the database?
- The corollary question - how would the second flow know when to fetch results for pushing into Elasticsearch? Periodic polling?
Thanks for any insight anyone can give me regarding this, I’d be happy to consider any other bits of tech stack people might have if there was an entirely better way to approach it as I’d like this to be as robust as possible.
I appreciate this isn’t primarily an Nifi question and I haven’t considered any CDC process here to capture updates to the datasets so I’d imagine this would get even more complicated…
P.S. I’ve watched the HortonWorks talk here https://youtu.be/fblkgr1PJ0o?t=3149 which I found helpful and mentioned these community forums.
Cheers,
Gavin.
Created 08-16-2018 04:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am currently using NiFi to solve your criteria.
A NiFi Processor Group handles Elasticsearch (ScrollElasticsearchHttp) -> attribute/string of XML -> Parsed XML Object as Json -> Additional Data From SQL -> Merged Data -> Kafka Topic. The Kafka Topic is configured for Data Compaction (de-duplication) based on an index id. A Second NiFi Processor Group uses GetKafka and sends those unique results to PutElasticSearchHttp creating the final unique elastic document.
There are many ways to skin this cat, but to answer your questions:
1 NiFi is excellent for multiple data sources and the approach is extremely feasible.
2. Data compaction and "exactly once" via kafka is just some basic topic settings.
3. The NiFi Scroll ElasticSearch processor has a state allowing it to roll through an index indefinitely never skipping any ids.
If this answer is helpful, please choose Accept.
Created 08-16-2018 04:17 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am currently using NiFi to solve your criteria.
A NiFi Processor Group handles Elasticsearch (ScrollElasticsearchHttp) -> attribute/string of XML -> Parsed XML Object as Json -> Additional Data From SQL -> Merged Data -> Kafka Topic. The Kafka Topic is configured for Data Compaction (de-duplication) based on an index id. A Second NiFi Processor Group uses GetKafka and sends those unique results to PutElasticSearchHttp creating the final unique elastic document.
There are many ways to skin this cat, but to answer your questions:
1 NiFi is excellent for multiple data sources and the approach is extremely feasible.
2. Data compaction and "exactly once" via kafka is just some basic topic settings.
3. The NiFi Scroll ElasticSearch processor has a state allowing it to roll through an index indefinitely never skipping any ids.
If this answer is helpful, please choose Accept.
Created 08-16-2018 05:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Many thanks for your response.
That all sounds very interesting, I have no experience with Kafka but I will check it out and see if it fits into what I’m trying to achieve here.
Unless I’m misunderstanding - my major issue is not having a common identifier between datasets to deduplicate from so having to rely on an external tool (such as dedupe) to do some fancy data science work when clustering the duplicates e.g. looking at forename, surname, address and deciding if it should be clustered.
There is also an element of training involved which would need to happen externally to further confuse things as it is an external tool. I suppose if I enriched the data with a common cluster id I could then fire this to Kafka for the data compaction bit which would match what you have above.
Anyway, good to know I’m going along the right track so thanks again for your answer - ScrollElasticsearchHttp is interesting to read about!
Cheers!
Gavin.
Created 08-16-2018 05:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Accept the answer to make it answered for others.
You are correct, the particular implementation for your use case scenario can be accomplished in many ways. The morale should be that NiFi and other hadoop based components are true winners. Also working with new components keeps things exciting. You would not be making an unwise decision to embrace NiFi.

