Support Questions
- Cloudera Community
- Support
- Support Questions
- DBCP connection pool Issue(Can't load Database Dri...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
DBCP connection pool Issue(Can't load Database Driver) in NiFi in Linux box (Centos 7)
- Labels:
-
Apache NiFi
Created 06-07-2018 07:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
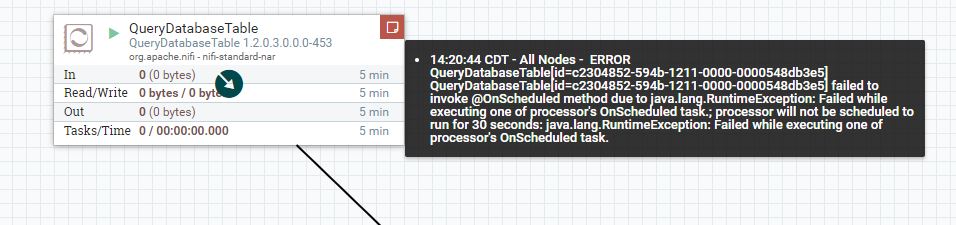
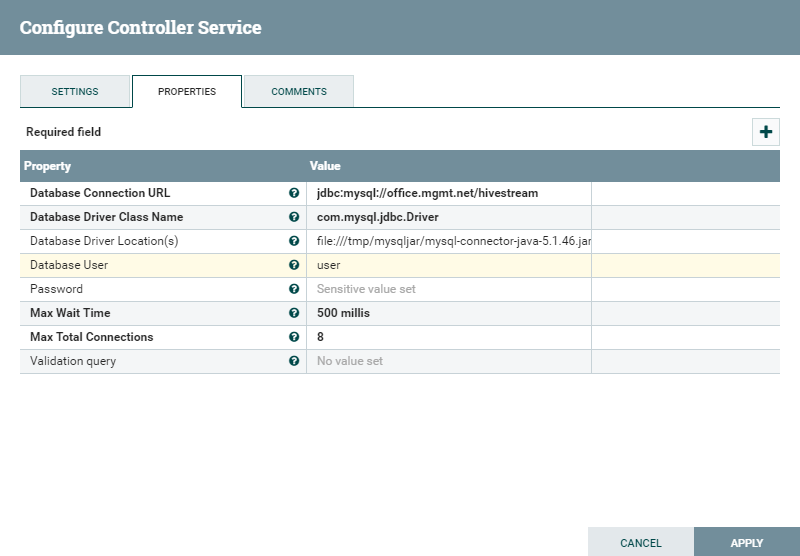
I'm unable to establish connection between Mysql and Hive due to DBCP connection pool .This is my configuration settings in DBCP connection pool ( please refer attached) . I'm getting error says (refer attached ) dbcp1.jpg dbcp2.jpg
Query database table -> put hive streaming processors is used . and Query Database table is scheduled to run every three minutes .
I have restarted Nifi by disabling the DBCP connection pool and tried . Still the same and failed .
Also Is it possible to insert updated values + New values in Mysql to Hive ( which processor should I use)
@Matt Clarke @Matt Burgess . Could you please have a look here please . what am I doing wrong .
Thanks All
Created 06-07-2018 10:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try without file:// in your Database Driver Location(s) value i.e
/tmp/mysqljar/mysql-connector-java-5.1.46.jar
Check permissions and driver is on all the NiFi cluster nodes.
-
Is it possible to insert updated values + New values in Mysql to Hive?
Yes, it's possible only if you are having some sort of identifier field that you could tell it's an updated record in the source table.
Usually when record gets updated/created in the RDBMS tables, add current timestamp to the record to the record then in NiFi using QueryDatabaseTable processor Maximum-value Columns property with the timestamp field then the processor will store the state and pulls only the incremental records(updated records+ New records).
Created 06-07-2018 10:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try without file:// in your Database Driver Location(s) value i.e
/tmp/mysqljar/mysql-connector-java-5.1.46.jar
Check permissions and driver is on all the NiFi cluster nodes.
-
Is it possible to insert updated values + New values in Mysql to Hive?
Yes, it's possible only if you are having some sort of identifier field that you could tell it's an updated record in the source table.
Usually when record gets updated/created in the RDBMS tables, add current timestamp to the record to the record then in NiFi using QueryDatabaseTable processor Maximum-value Columns property with the timestamp field then the processor will store the state and pulls only the incremental records(updated records+ New records).
Created on 06-08-2018 08:45 PM - edited 08-17-2019 08:01 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We cannot load the sample table that you have shared incrementally because
let's take you have used QueryDatabaseTable and given max value column as id then processor will pulls(id's 1,2,3) in the first run and stores the state as 3 after the first run.
Second run processor pulls only the records that are greater than id>3 now we are not able to pull 1,3 records as they are updated ,Processor will pull only id=4 and updates the state to 4.
1.How can we pull data incrementally from RDBMS table then?

{kind=link}
{kind=link}
{kind=link}
Let's consider your table having one more extra column i.e update_at(timestamp type) this field will be updated with system timestamp when there is new records inserted/created in the table (or) records got updated in the table.
Initially you are having 3 records that are created at 2017-01-01 12:00:00.00 and then id's 1,3 updated and 4 created with new updated_at timestamp i.e 2018-06-08 12:00:00.00.
Now you have configured QueryDatabaseTable processor with max value column as updated_at so
- first run processor pulls all the id's(1,2,3) and updates the state as 2017-01-01 12:00:00.00
- next run processor checks for any updated values after 2017-01-01 12:00:00.00 if it founds then pulls all the records and updates the state to 2018-06-08 12:00:00.00(in our case).
By using this table structure we are going to capture all the updates that are happening on the source table to Hive table.
2.On the second load , We have to remove the values 3 and update the value 1 and insert the value 4 . How that is possible in Nifi . Is that at possible ?
Update/Deletes in Hive through NiFi is not yet possible(hive natively don't support update/deletes) every thing will be appends to the hive table.
Approach1:
Look into Hive Acid Merge strategy described in this link will best fit for your needs.
In this article describes merge strategy
- when matched record found on the final table then define which action you need to take either Update (or) Delete
- if the record not matched in the final dataset then insert the record.
To use this merge strategy your source table needs to be designed in a way that you can capture all the updates that are happening in the table.
The final table in hive needs to be Acid enabled table to support merge functionality and Make sure your hive version supports this merge strategy.
Approach2:
- Capture all the incremental data to hive table then use window function to get only the latest record from the table
- It's always best practice to keep ingestion_timestamp field to each record that is storing into Hive..etc.
- So while retrieving the data from Hive use window function using Row_Number() to get most recent record by using where row_number=1 .
- Use predicate push downs while selecting data so that we are minimizing the data that would go to this window functions.
- By following this way if we are already having duplicated data also we are going to get only the most recent record.
- Even you can run some dedupe kind of jobs(using row_number) on hive table like once a week which is going to clean up the table that can eliminate duplicates in the table.
- References regarding implementation of row_number function
- If you enabled Acid transactions to the hive table also we need to prepare hive statements(i.e. need to know how to identify which record is updated/inserted/deleted) i.e update table <table-name>... to update the record and to delete the record prepare statement to delete the record in NiFi and execute the statement/s using PutHiveQL processor.
- If the table having million records and we are trying to update/delete one record,This process will be very intense and resource consuming as for each record we are doing insert/update/delete DML statements.
-
Click on Accept button below, if you feel like the answer addressed your question..!!
Created 06-08-2018 06:58 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I was able to establish a connection between mysql and Hive . However the purpose is not solved yet . I was trying to update and insert values into Hive . For Example ( refer attached) .
In the example : . On Initial load Hive has loaded the values of ID 1,2 and 3 . On the second load , We have to remove the values 3 and update the value 1 and insert the value 4 . How that is possible in Nifi . Is that at possible ?
Could please guide me on this If you can.
thanks ...
{kind=link}
Created 06-09-2018 03:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fantastic and detailed reply. I would try this out and reply if that works .Thanks a lot @Shu

