Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Error in publishing to Kafka topic in Nifi
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Error in publishing to Kafka topic in Nifi
- Labels:
-
Apache Kafka
-
Apache NiFi
Created 05-22-2018 09:10 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have a node "A" with RPG process that reads from a file of size 1.2GB roughly containing 20 million records and at the node "B" this file is received via an input port to pass on further to PublishKafka0_11. However, as soon as I do this the data gets sent from A and received till B but appears permanently in the state of queued before the "PublishKafka" processor.
To check if my flow was right I tried to read a file of 53.4kB and that gets sent to the processor succesfully and also into the topic named "INPUT_TOPIC" .
Here are the problems:
1) with 1.2 GB sized file, it does not seem to send the data into topic
2) After using 1.2 GB, the input port hangs or stops responding, also the processor "PublishKafka0_11" stops responding.
3) I used cat command manually to right into the topic "INPUT_TOPIC" to read into the consumer in the command line interface. However, when I check the logs for that "INPUT_TOPIC logs, there are two logs created both of which contain different texts in between (Almost binary gibberish) and the wc -l reads different numbers on both logs, adding to more than 20 million lines. I have tried this by removing the topic and doing afresh as well. But still the same type of output.
Can someone help me in this situation. My purpose is to load an input topic of kafka with my 20 million records. NO more, no less than 20 million.
Created 05-23-2018 02:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Increasing the back-pressure threshold will allow you to send more data to the input port, but it won't help make PublishKafka work.
Where does the 1.2GB file come from and how does it get sent to the input port?
I'm wondering if you can create multiple smaller files, instead of one huge file, and see if that helps at all.
Created 05-22-2018 01:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When the flow file is in the queue before PublishKafka, is there a number like "1" in the top right corner of PublishKafka?
If so, this means there is a thread processing the flow file, and we need to see what it is doing which can be done by taking a thread dump:
./bin/nifi.sh dump dump.txt
Please provide the contents of dump.txt
Created 05-23-2018 04:19 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
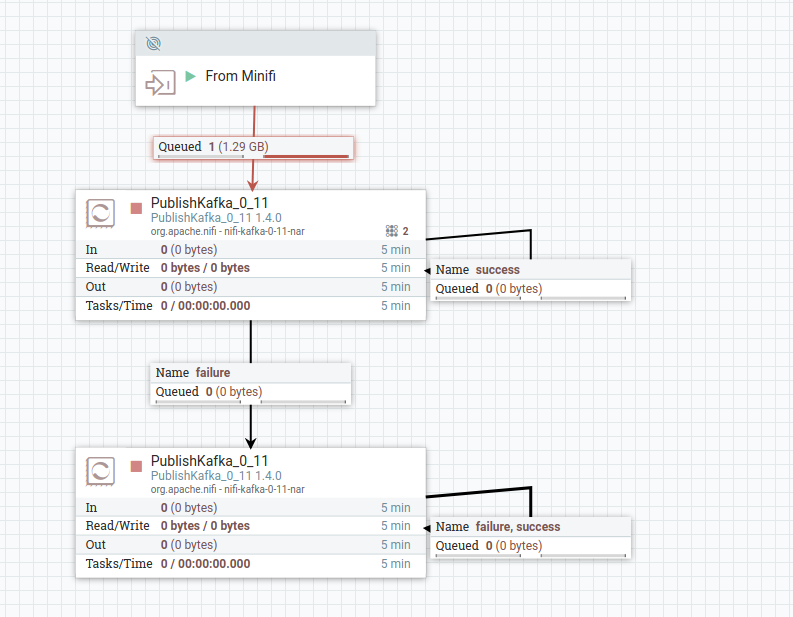{kind=link}
Hey @Bryan Bende thanks for replying. This is the flow in the image, you may be able to tell better if you see I thought. Before taking the dump, I tried to start the publish kafka processor but could not do so, as I receive the error "No eligible components are selected. Please select the components to be started and ensure they are no longer running."
And the start option is not available when I right click on the processor. However I still took the dump as asked. Attaching the dump file here. dump.txt
Please suggest me a method to send the data.
Created 05-23-2018 01:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the info...
From the looking at the picture, the reason the input port stops working is because back-pressure has occurred on the queue between the input port and PublishKafka, which you can tell from the red indicator on the queue. When back-pressure engages it means the component before the queue is no longer scheduled to run until the queue has gone below the threshold. You can configure the threshold by right-clicking on the queue, I believe it defaults to 10,000 flow files or 1GB of total size, which has been exceeded with the 1.2GB flow file.
As far as PublishKafka... as far as I can tell, the thread dump does not show a stuck thread, it shows that a thread for PublishKafka is reading the 1.2 GB file from NiFi's content repository.
How long have you waited to see if it finishes? I would assume it could take a while to read and send 1.2 GB to Kafka.
Created 05-23-2018 02:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have waited overnight, and still has been stuck in this state only. Should I increase the said value of 1GB in the back pressure to 2GB and then check?
Created 05-23-2018 02:20 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Increasing the back-pressure threshold will allow you to send more data to the input port, but it won't help make PublishKafka work.
Where does the 1.2GB file come from and how does it get sent to the input port?
I'm wondering if you can create multiple smaller files, instead of one huge file, and see if that helps at all.
Created 05-23-2018 02:29 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
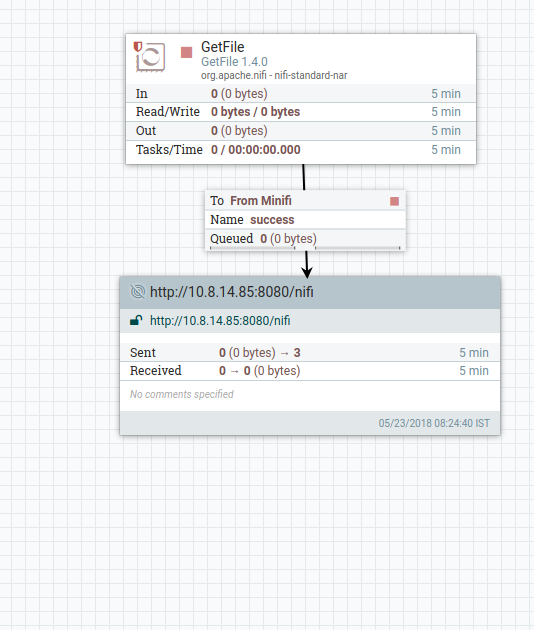{kind=link}
Here is the node A processor picture that I have attached. Ideally I want one input topic to receive 20 million records from a local file or sent via nifi processor. I think your idea of splitting it into chunks of multiple files should do too.
Created 05-23-2018 02:47 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What format is the data being picked up by GetFile? I'm assuming new-line delimited text?
There are several options that could be used between GetFile and the RPG to split it up, but you would need to use an approach that splits correctly on the logical boundaries of the data in the file.
Ideally whatever is producing the file before NiFi could produce multiple smaller files.
Created 05-25-2018 07:02 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Bryan Bende I tried the multiple files thing before GetFile, and it worked really fast.
Although I have 4 additional questions. Two are observations and 2 research questions.
1) Now that I have a flow now like "GetFile-> PublishKafka0_11->PutFile"(see attached pic)
horton.png , the folder that contains 2000 files(originally one large file was csv, now it does not seem to have a csv extension or any extension at all) is read in GetFile processor. And then after reading straightaway published to Kafka topic called new_profiler_testing and if it is successful, it should send it to PutFile, where it puts all these files read into a Folder called output.
This happens to generate the log files in kafka-logs, as I wanted to check the topic "new_profiler_testing"
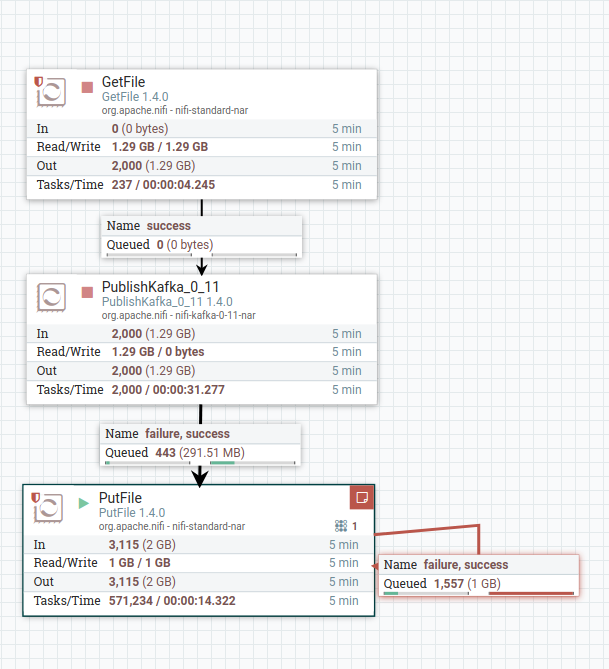{kind=link}
Now, if I count the number of lines in this log file they are
1231264 00000000000000062200.log
and if I check for number of files written into the output folder they are 1561. You may have observed from the picture, that there is congestion that again happens at the PutFile end after success message is delivered from PublishKafka0_11.
I want to check for my 2million records in kafka topic. How do I do that? Because when I open the log file in kafka-logs, it seems to have gibberrish content as well. Do you think I should simultaneously open a consumer console and pipe it via wc -l? or is there a way by which I can do it in Nifi
2) I ran this process twice in order to make sure its running, and the first time something strange happened. The output folder contained files like these xzbcl.json xzbcm.json xzbcn.json xzbco.json xzbcp.json xzbcq.json xzbcr.json xzbcs.json xzbcy.json xzbcz.json and also xzbcl, xzbcm, xzbcn, xzbco, xzbcp, xzbcq, xzbcr, xzbcs, xzbcy, xzbcz, along with other normal files.
And they were in the format of json when I opened them. Here is a snippet
[{"timestamp":1526590200,"tupvalues":[0.1031287352688188,0.19444490419773347,0.06724761719024923,0.008715105948727752,0.273251449860885,0.09916421288937546,0.12308943665971132,0.017852488055395015,0.05039765141148139,0.11335172723104833,0.03305334889471589,0.041821925451222756,0.08485309865154911,0.09606502178530299,0.06843417769071786,0.024991363178388175, 0.2800309262376106,0.1926730050165331,0.2785879089696489,0.211383486088693...]}]
Why did this happen and how? Also the size of the then created log was 785818 00000000000000060645.log. Is it possible that the number of records written into a topic varies over time and is susceptible to change?
Also, this is the format I would ideally want my kafka topic to be in(ie. json format). But have not been able to get around that, as mentioned in this post by me https://community.hortonworks.com/questions/191753/csv-to-json-conversion-error.html?childToView=191...
3) If I have ten files in Nifi being read from same folder, how is the data read? Is it read one after the other in the order and pushed to kafka? Or is it randomly sent? I want to know because I have a program written in kafka-streams that needs to group by on timestamp values. For eg. today 10am-11am data from all ten folders to be averaged for their CPU usages.
4) Is there a way to time my output into kafka topic. I would like to know how much time it takes for GetFile to read the files and then send to kafka topic completely till it has 2million records?

