Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: HDFS Balancer exits without balancing
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
HDFS Balancer exits without balancing
Created 05-28-2017 11:07 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Command ran through shell script:
....Logging sudo -u hdfs -b hdfs balancer -threshold 5 ....
Log: The Balance exits successfully without balancing.
17/05/26 16:38:51 INFO balancer.Balancer: Using a threshold of 5.0 17/05/26 16:38:51 INFO balancer.Balancer: namenodes = [hdfs://belongcluster1] 17/05/26 16:38:51 INFO balancer.Balancer: parameters = Balancer.BalancerParameters [BalancingPolicy.Node, threshold = 5.0, max idle iteration = 5, #excluded nodes = 0, #included nodes = 0, #source nodes = 0, #blockpools = 0, run during upgrade = false] 17/05/26 16:38:51 INFO balancer.Balancer: included nodes = [] 17/05/26 16:38:51 INFO balancer.Balancer: excluded nodes = [] 17/05/26 16:38:51 INFO balancer.Balancer: source nodes = [] Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved 17/05/26 16:38:53 INFO balancer.KeyManager: Block token params received from NN: update interval=10hrs, 0sec, token lifetime=10hrs, 0sec 17/05/26 16:38:53 INFO block.BlockTokenSecretManager: Setting block keys 17/05/26 16:38:53 INFO balancer.KeyManager: Update block keys every 2hrs, 30mins, 0sec 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.movedWinWidth = 5400000 (default=5400000) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.moverThreads = 1000 (default=1000) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.dispatcherThreads = 200 (default=200) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.datanode.balance.max.concurrent.moves = 5 (default=5) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.getBlocks.size = 2147483648 (default=2147483648) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.getBlocks.min-block-size = 10485760 (default=10485760) 17/05/26 16:38:53 INFO block.BlockTokenSecretManager: Setting block keys 17/05/26 16:38:53 INFO balancer.Balancer: dfs.balancer.max-size-to-move = 10737418240 (default=10737418240) 17/05/26 16:38:53 INFO balancer.Balancer: dfs.blocksize = 134217728 (default=134217728) 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.144.YYY:50010 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.144.YYY:50010 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.145.YY:50010 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.145.YY:50010 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.145.YY:50010 17/05/26 16:38:53 INFO net.NetworkTopology: Adding a new node: /default-rack/58.XXX.144.YY:50010 17/05/26 16:38:53 INFO balancer.Balancer: 0 over-utilized: [] 17/05/26 16:38:53 INFO balancer.Balancer: 0 underutilized: [] The cluster is balanced. Exiting... May 26, 2017 4:38:53 PM 0 0 B 0 B -1 B May 26, 2017 4:38:54 PM Balancing took 2.773 seconds
The Ambari Host view indicates that the data is still not balanced across the nodes:
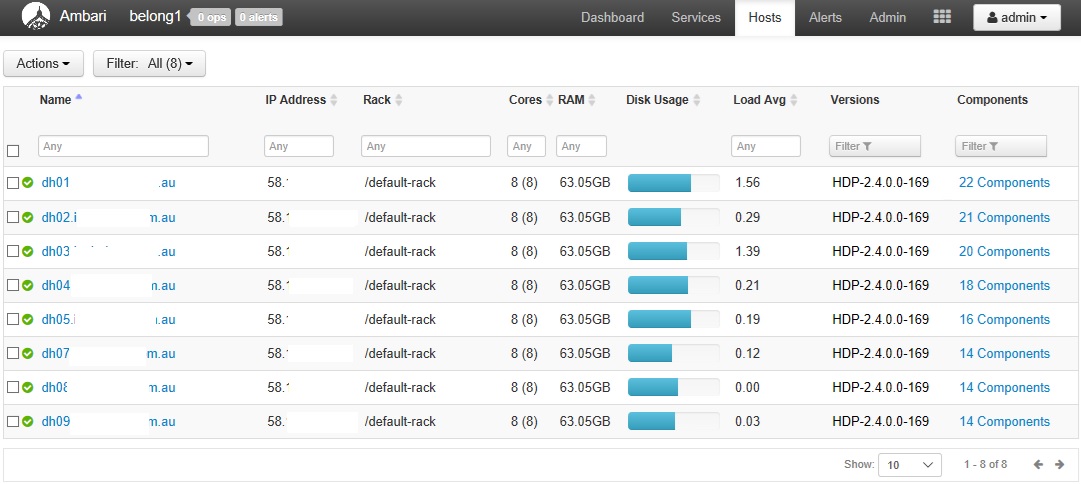{kind=link}
( Updated) The cluster has HA configuration (Primary-Secondary).
Ambari : 2.2.1.0
Hadoop : 2.7.1.2.4.0.0-169
Any input will be helpfull.
Created 05-29-2017 12:21 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- sudo -u hdfs -b hdfs balancer -threshold 5
What do you have "-b" for in this command? Shouldn't this be
sudo -u hdfs hdfs balancer -threshold 5
Created 05-29-2017 12:30 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@mqureshi I used "-b" option to push the processing to background. I have also tried the following from server that has NN. Trial 1: (on Command Prompt)
nohup sudo -u hdfs hdfs balancer -threshold 5 > /var/log/hadoop/hdfs/balancer.$(date +%F_%H-%M-%S.%N).log 2>&1 &Trial 2: (on Command Prompt) . DH05 needs to be offloaded as its the most unbalanced
sudo -u hdfs -b hdfs balancer -threshold 5 -source DH05 > /var/log/hadoop/hdfs/balancer.$(date +%F_%H-%M-%S.%N).log 2>&1 &
I get the same output from Balancer as it exists stating that "The cluster is balanced". It's somehow not able to get the current stats on data in the datanodes.
Created 05-29-2017 12:54 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you also have a standby namenode? Can you try the following:
sudo -u hdfs -b hdfs balancer -fs hdfs://<your name node>:8020 -threshold 5
Created 05-29-2017 02:17 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@mqureshi The cluster has a primary and secondary configuration for NN. When i run the balance command as you indicated, i get an error stating "Another Balancer is running". But ps -ef | grep balancer does not show any running balancer process
[root@dh01 ~]# sudo -u hdfs hdfs balancer -fs hdfs://dh01.int.belong.com.au:8020 -threshold 5 17/05/29 12:14:53 INFO balancer.Balancer: Using a threshold of 5.0 17/05/29 12:14:53 INFO balancer.Balancer: namenodes = [hdfs://belongcluster1, hdfs://dh01.int.belong.com.au:8020] 17/05/29 12:14:53 INFO balancer.Balancer: parameters = Balancer.BalancerParameters [BalancingPolicy.Node, threshold = 5.0, max idle iteration = 5, #excluded nodes = 0, #included nodes = 0, #source nodes = 0, #blockpools = 0, run during upgrade = false] 17/05/29 12:14:53 INFO balancer.Balancer: included nodes = [] 17/05/29 12:14:53 INFO balancer.Balancer: excluded nodes = [] 17/05/29 12:14:53 INFO balancer.Balancer: source nodes = [] Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved 17/05/29 12:14:54 INFO balancer.KeyManager: Block token params received from NN: update interval=10hrs, 0sec, token lifetime=10hrs, 0sec 17/05/29 12:14:54 INFO block.BlockTokenSecretManager: Setting block keys 17/05/29 12:14:54 INFO balancer.KeyManager: Update block keys every 2hrs, 30mins, 0sec 17/05/29 12:14:55 INFO block.BlockTokenSecretManager: Setting block keys 17/05/29 12:14:55 INFO balancer.KeyManager: Block token params received from NN: update interval=10hrs, 0sec, token lifetime=10hrs, 0sec 17/05/29 12:14:55 INFO block.BlockTokenSecretManager: Setting block keys 17/05/29 12:14:55 INFO balancer.KeyManager: Update block keys every 2hrs, 30mins, 0sec java.io.IOException: Another Balancer is running.. Exiting ... May 29, 2017 12:14:55 PM Balancing took 2.431 seconds
Created 05-29-2017 02:26 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Check this link if you have the same issue:
https://community.hortonworks.com/articles/4595/balancer-not-working-in-hdfs-ha.html
Created 05-29-2017 02:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
About : https://community.hortonworks.com/articles/4595/balancer-not-working-in-hdfs-ha.html
my hdfs-site.xml has 2 entries .. i am not sure if i need to delete both or NN2 only..
<property>
<name>dfs.namenode.rpc-address.belongcluster1.nn1</name>
<value>dh01.int.belong.com.au:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.belongcluster1.nn2</name>
<value>dh02.int.belong.com.au:8020</value>
</property>
Created 05-29-2017 02:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think you should have only one value and it should point to your "name service". You should have a value for name service when you have HA enabled. See the following link on how this works in HA - third row:
https://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
Created 05-29-2017 03:40 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@mqureshi I found another thread with similar issue: https://community.hortonworks.com/questions/22105/hdfs-balancer-is-getting-failed-after-30-mins-in-a... here they say indicate that if HA is enabled then one would need to remove dfs.namenode.rpc-address . I ran a check on Ambari Server using the configs.sh:
/var/lib/ambari-server/resources/scripts/configs.sh -u admin -p admin -port 8080 get dh01.int.belong.com.au belong1 hdfs-site
and the output does not contain the dfs.namenode.rpc-address property.
########## Performing 'GET' on (Site:hdfs-site, Tag:version1470359698835)
"properties" : {
"dfs.block.access.token.enable" : "true",
"dfs.blockreport.initialDelay" : "120",
"dfs.blocksize" : "134217728",
"dfs.client.block.write.replace-datanode-on-failure.enable" : "NEVER",
"dfs.client.failover.proxy.provider.belongcluster1" : "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"dfs.client.read.shortcircuit" : "true",
"dfs.client.read.shortcircuit.streams.cache.size" : "4096",
"dfs.client.retry.policy.enabled" : "false",
"dfs.cluster.administrators" : " hdfs",
"dfs.content-summary.limit" : "5000",
"dfs.datanode.address" : "0.0.0.0:50010",
"dfs.datanode.balance.bandwidthPerSec" : "6250000",
"dfs.datanode.data.dir" : "/data/hadoop/hdfs/data",
"dfs.datanode.data.dir.perm" : "750",
"dfs.datanode.du.reserved" : "1073741824",
"dfs.datanode.failed.volumes.tolerated" : "0",
"dfs.datanode.http.address" : "0.0.0.0:50075",
"dfs.datanode.https.address" : "0.0.0.0:50475",
"dfs.datanode.ipc.address" : "0.0.0.0:8010",
"dfs.datanode.max.transfer.threads" : "16384",
"dfs.domain.socket.path" : "/var/lib/hadoop-hdfs/dn_socket",
"dfs.encrypt.data.transfer.cipher.suites" : "AES/CTR/NoPadding",
"dfs.encryption.key.provider.uri" : "",
"dfs.ha.automatic-failover.enabled" : "true",
"dfs.ha.fencing.methods" : "shell(/bin/true)",
"dfs.ha.namenodes.belongcluster1" : "nn1,nn2",
"dfs.heartbeat.interval" : "3",
"dfs.hosts.exclude" : "/etc/hadoop/conf/dfs.exclude",
"dfs.http.policy" : "HTTP_ONLY",
"dfs.https.port" : "50470",
"dfs.journalnode.edits.dir" : "/hadoop/hdfs/journal",
"dfs.journalnode.https-address" : "0.0.0.0:8481",
"dfs.namenode.accesstime.precision" : "0",
"dfs.namenode.acls.enabled" : "true",
"dfs.namenode.audit.log.async" : "true",
"dfs.namenode.avoid.read.stale.datanode" : "true",
"dfs.namenode.avoid.write.stale.datanode" : "true",
"dfs.namenode.checkpoint.dir" : "/tmp/hadoop/hdfs/namesecondary",
"dfs.namenode.checkpoint.edits.dir" : "${dfs.namenode.checkpoint.dir}",
"dfs.namenode.checkpoint.period" : "21600",
"dfs.namenode.checkpoint.txns" : "1000000",
"dfs.namenode.fslock.fair" : "false",
"dfs.namenode.handler.count" : "200",
"dfs.namenode.http-address" : "dh01.int.belong.com.au:50070",
"dfs.namenode.http-address.belongcluster1.nn1" : "dh01.int.belong.com.au:50070",
"dfs.namenode.http-address.belongcluster1.nn2" : "dh02.int.belong.com.au:50070",
"dfs.namenode.https-address" : "dh01.int.belong.com.au:50470",
"dfs.namenode.https-address.belongcluster1.nn1" : "dh01.int.belong.com.au:50470",
"dfs.namenode.https-address.belongcluster1.nn2" : "dh02.int.belong.com.au:50470",
"dfs.namenode.name.dir" : "/data/hadoop/hdfs/namenode",
"dfs.namenode.name.dir.restore" : "true",
"dfs.namenode.rpc-address.belongcluster1.nn1" : "dh01.int.belong.com.au:8020",
"dfs.namenode.rpc-address.belongcluster1.nn2" : "dh02.int.belong.com.au:8020",
"dfs.namenode.safemode.threshold-pct" : "0.99",
"dfs.namenode.shared.edits.dir" : "qjournal://dh03.int.belong.com.au:8485;dh02.int.belong.com.au:8485;dh01.int.belong.com.au:8485/belongcluster1",
"dfs.namenode.stale.datanode.interval" : "30000",
"dfs.namenode.startup.delay.block.deletion.sec" : "3600",
"dfs.namenode.write.stale.datanode.ratio" : "1.0f",
"dfs.nameservices" : "belongcluster1",
"dfs.permissions.enabled" : "true",
"dfs.permissions.superusergroup" : "hdfs",
"dfs.replication" : "3",
"dfs.replication.max" : "50",
"dfs.support.append" : "true",
"dfs.webhdfs.enabled" : "true",
"fs.permissions.umask-mode" : "022",
"nfs.exports.allowed.hosts" : "* rw",
"nfs.file.dump.dir" : "/tmp/.hdfs-nfs"
}
Are you suggesting that i just keep 1 namenode service address and point it to primary name node host:port. Something like the below:
<property>
<name>dfs.namenode.rpc-address.belongcluster1</name>
<value>dh01.int.belong.com.au:8020</value>
</property>
Created 05-29-2017 05:24 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually, don't delete anything. Your version of Ambari does not seem to be affected by this bug. Try the following:
sudo -u hdfs -b hdfs balancer -fs hdfs://belongcluster1:8020 -threshold 5
My guess is you were only missing port number. Can you please try it.

