Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Initial job has not accepted any resources
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Initial job has not accepted any resources
Created 06-02-2016 12:22 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
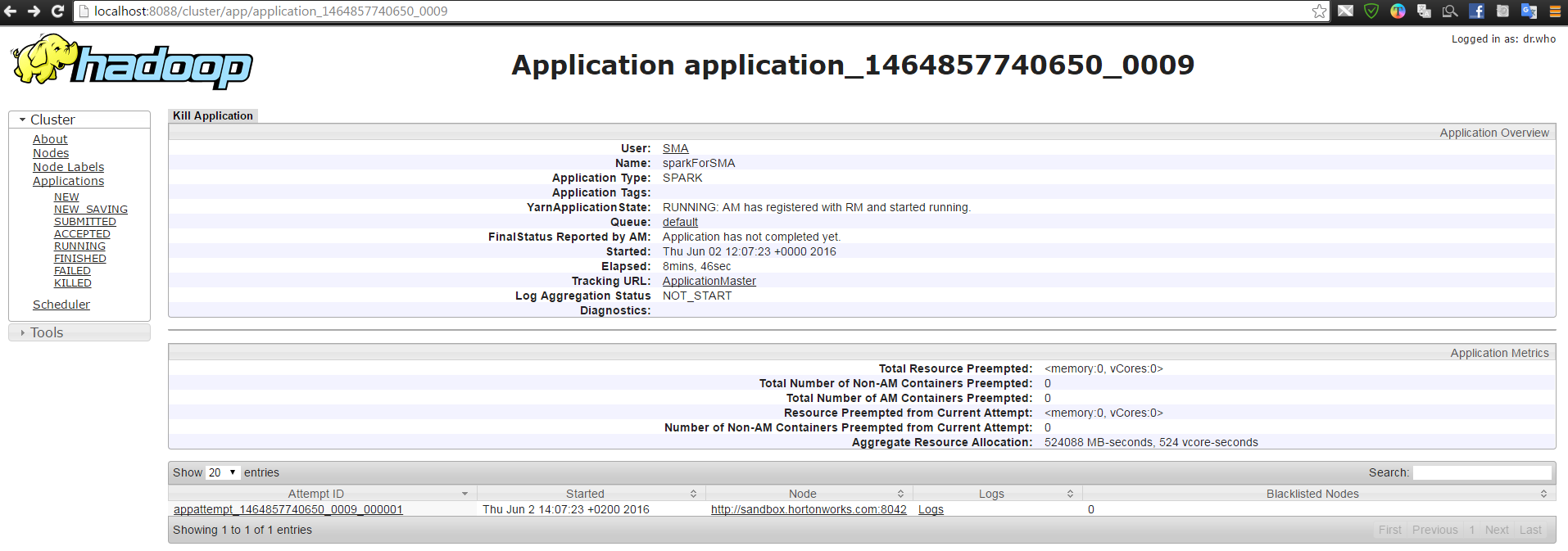
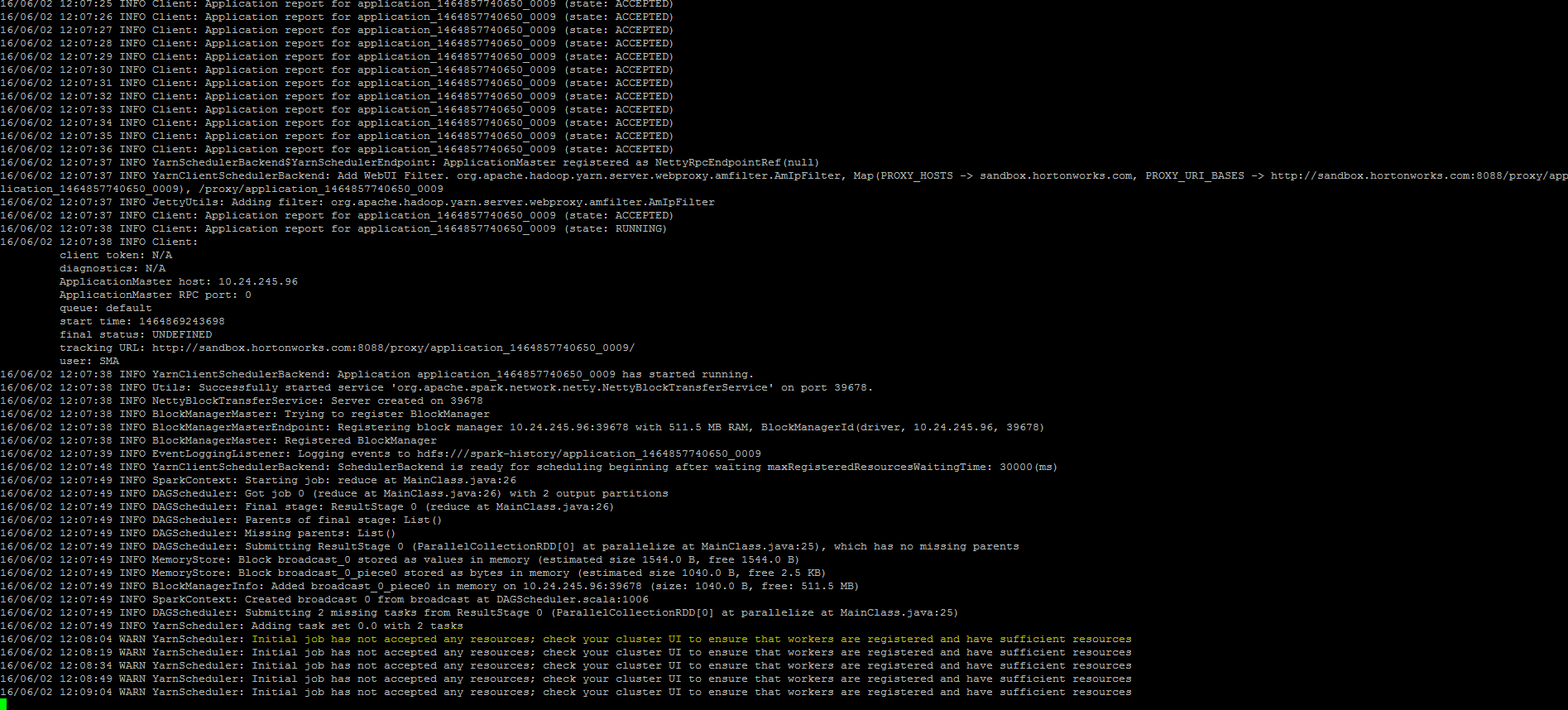
clusterurl.pnglogurlpng.pngterminal.pngI am using Sandbox 2.4 , I created a simple Spark Java application with the following conif.
{kind=link}
{kind=link}
{kind=link}
SparkConf conf = new SparkConf().setAppName("spark").set("spark.master", "yarn-client");I packaged a Jar and used spark-submit to run the app
but I got the following error.
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
I opened the URL
http://localhost:8088/cluster/app/application_1464857740650_0009
and clicked on the log link to see the log, but I got
Access Denied.
I attached couple of photos to give a clear idea what's going on with me
thank you for your help.
Created 06-02-2016 01:48 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
can you post the spark-submit you listed?
Created 06-02-2016 01:52 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tried different command to submit the job
spark-submit --class com.Spark.MainClass /home/Test-0.0.1-SNAPSHOT.jar
and
spark-submit --class com.Spark.MainClass -master yarn-client /home/Test-0.0.1-SNAPSHOT.jar
Created 06-02-2016 02:08 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You really need more cores. But 2 may work.
spark-submit --class "com.stuff.Class" \ --master yarn --deploy-mode client --driver-memory 1024m --executor-memory 1024m --conf spark.ui.port=4244 MyJar.jar
remove this from your code
.set("spark.master","yarn-client");
add this
sparkConf.set("spark.cores.max", "1")
sparkConf.set("spark.serializer", classOf[KryoSerializer].getName)
sparkConf.set("spark.sql.tungsten.enabled", "true")
sparkConf.set("spark.eventLog.enabled", "true")
sparkConf.set("spark.app.id", "YourId")
Created 06-02-2016 02:11 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you please explain to me what the following line mean
sparkConf.set("spark.serializer", classOf[KryoSerializer].getName)
Created 06-02-2016 02:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
KryoSerializer is pretty awesome. It is a faster Java serializer. This will speed up Spark, not related to your issue, but I like to add that to all my Spark projects. When RDDs are in memory they are serialized objects. So a faster, smaller serialization will help with speed and memory.
Created 06-02-2016 04:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have faced this issue numerous times as well:
"“WARN YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources”
The problem was with Dynamic Resource Allocation over allocating. After turning off Dynamic Resource allocation and then specifying number of executors, executor memory, and cores, my jobs were running.
Turn off Dynamic Resource Allocation:
conf = (SparkConf()
.setAppName("my_job_name")
.set("spark.shuffle.service.enabled", "false")
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.io.compression.codec", "snappy")
.set("spark.rdd.compress", "true"))
sc = SparkContext(conf = conf)
Give values with spark submit (you could also set these in SparkConf as well):
/usr/hdp/2.3.4.0-3485/spark/bin/spark-submit --master yarn --deploy-mode client /home/ec2-user/scripts/validate_employees.py --driver-memory 3g --executor-memory 3g --num-executors 4 --executor-cores 2
- « Previous
-
- 1
- 2
- Next »

