Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Is it possible to install only ambari yarn and...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Is it possible to install only ambari yarn and spark ?
- Labels:
-
Apache Ambari
-
Apache Spark
-
Apache YARN
Created 09-01-2016 01:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
To avoid the standalone mode of Spark and use ambari to monitor my spark jobs, I was wondering if I could setup a HDP cluster with only ambari + spark + yarn without other components (or as little as possible) to avoid having too many nodes for just profiting of ambari/spark integration through yarn.
Thanks,
Nicolas
Created 09-02-2016 05:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
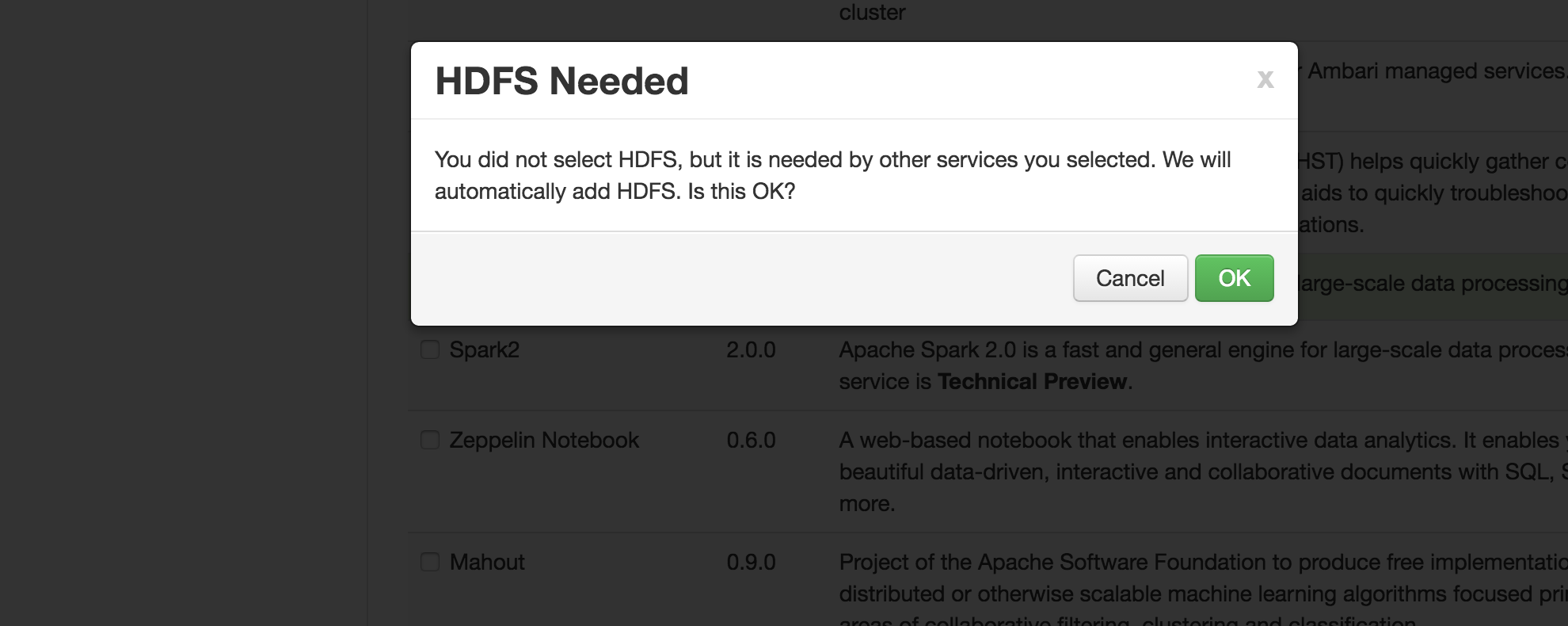
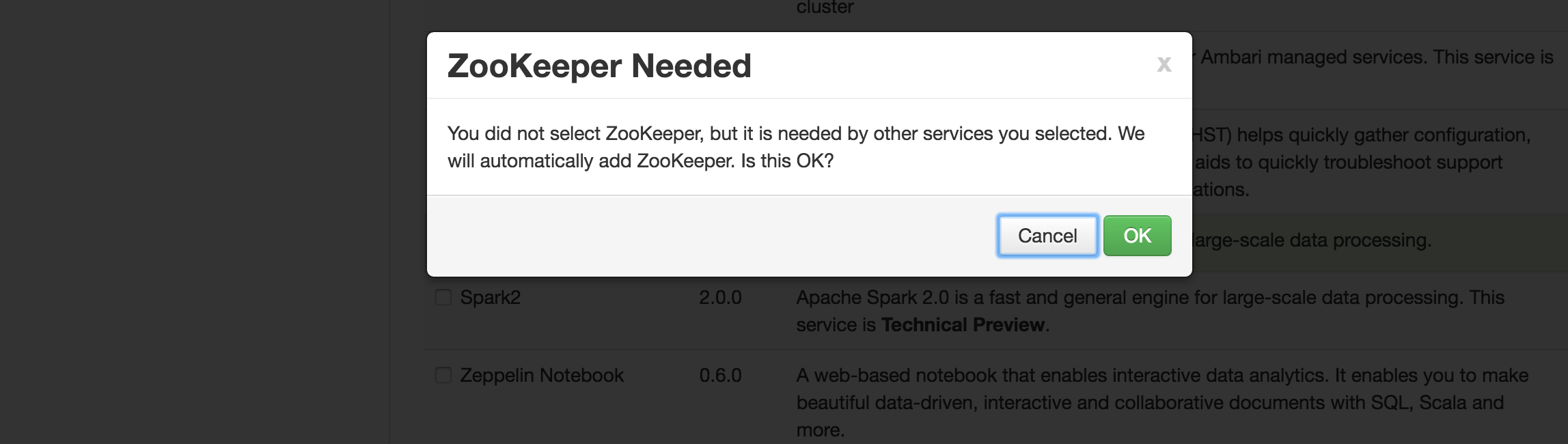
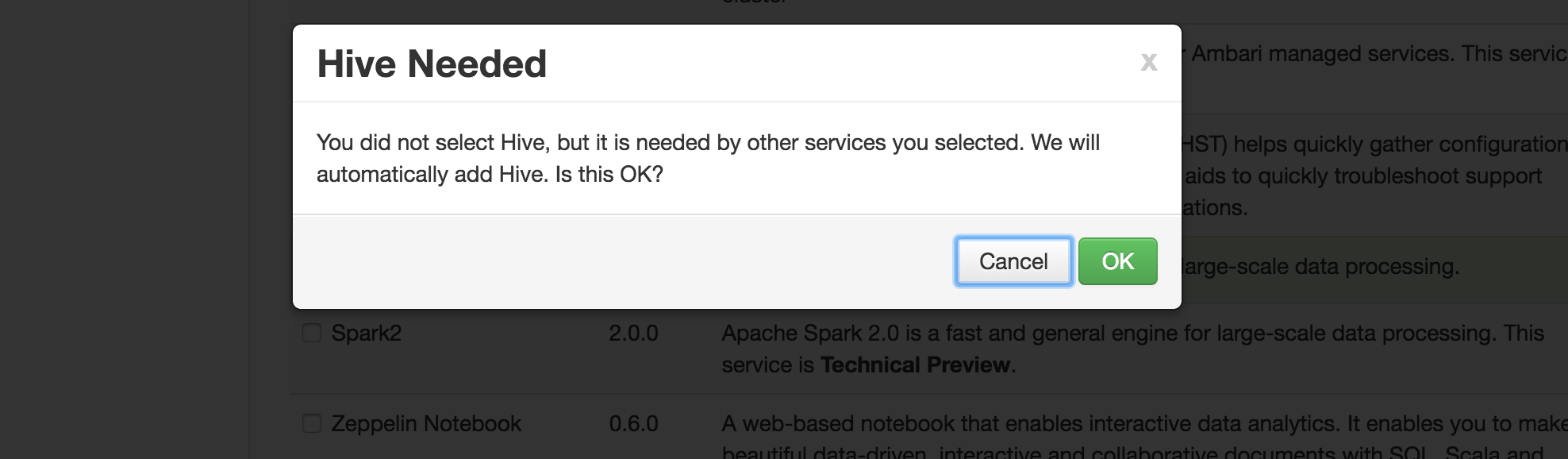
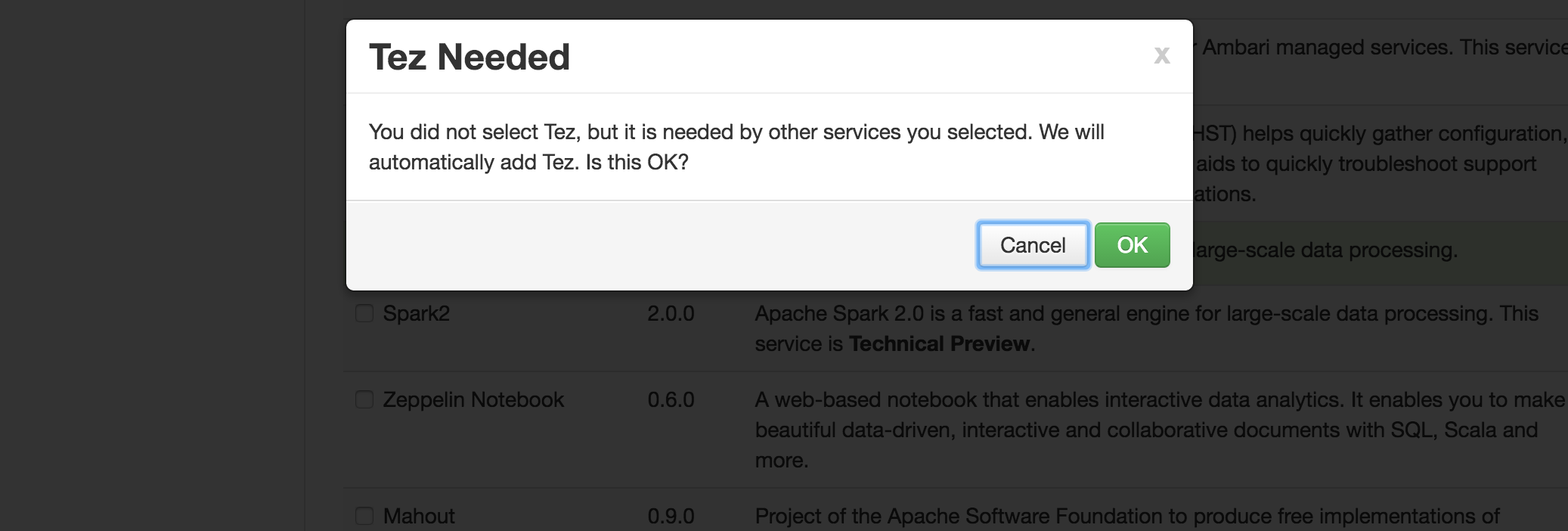
@Nicolas Steinmetz I just tested your usecase in my environment and below are the components that would be needed before you move forward:
1. HDFS
2. YARN
3 Zookeeper
4. MR
5. Hive
6. Pig Client - You can remove this after the installation is done
7. Slider client - You can remove this after the installation is done
8. Tez Client
9. It will give you a Warning for SmartSense and Ambari Metrics but you can by pass that.
10 . Spark
Note - I tested this with HDP 2.5 and Ambari 2.4.0.1
Please find the attached screenshot for reference.
untitled.pnguntitled-1.pnguntitled-2.pnguntitled-3.pnguntitled-4.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Created 09-01-2016 06:25 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I believe you would need HDFS, MR and Zookeeper in addition to Yarn and Spark. Ambari will not let you move forward without these components
Created 09-02-2016 04:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
At the bare minimum, you will need the cluster to have the following components: HDFS (data storage), MR (processing), Zookeeper (distributed coordination), YARN (Resource Manager), Ambari (components deployment and monitoring) and then Spark for your processing. Ambari will not proceed to deploy without these components.
Created 09-02-2016 05:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Nicolas Steinmetz I just tested your usecase in my environment and below are the components that would be needed before you move forward:
1. HDFS
2. YARN
3 Zookeeper
4. MR
5. Hive
6. Pig Client - You can remove this after the installation is done
7. Slider client - You can remove this after the installation is done
8. Tez Client
9. It will give you a Warning for SmartSense and Ambari Metrics but you can by pass that.
10 . Spark
Note - I tested this with HDP 2.5 and Ambari 2.4.0.1
Please find the attached screenshot for reference.
untitled.pnguntitled-1.pnguntitled-2.pnguntitled-3.pnguntitled-4.png
Created 09-05-2016 08:01 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @lraheja
Thanks for your precised answer (and thanks other people too 🙂 )
Side questions, it does not enforce having too many machines ? I would like to have a minimum sized cluster for this need.
Thanks,
Nicolas
Created 09-05-2016 05:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It would depend on your need. If dfs.replication is 3(default) - which means each block would be replicated to 3 Data Nodes then you would atleast need 3 machines and all should have Data Node on it. You can configure this value of in HDFS and you would need to have atleast those many machine. Usually one go for 5 node cluster - 1 Master Node, 3 Data Nodes and 1 Edge Node (All clients on it).
If your replication factor is 2 then you can build up a cluster with 2 Node too.
Created 09-06-2016 12:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @lraheja
Thanks for your precision ; I'll share this with other people in the team and see if we take this option or not.
Thanks a lot
Nicolas

