Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Load balancing while the fetching of file fro...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Load balancing while the fetching of file from a standalone NIFI instance doing the processing it in a NIFI cluster.
- Labels:
-
Apache NiFi
Created 08-24-2016 01:23 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have a NIFI setup where in we have a NIFI cluster installed in a hadoop cluster and a standalone NIFI instance running on another server.The input file will be generated in the file system of the server of the standalone instance.We are fetching the file using ListFile/FetchFile processor in the standalone instance.Then in the main cluster we are connecting to the standalone instance using RPG group and then send the output to the NIFI cluster(RPG) using site-site.As per my understanding the part of the processing done inside the cluster will be distributed.Is this understanding correct?I also would like to know if there is a way to distribute the fetching of the source file that we are doing in the standalone NIFI instance?
The flow we are using
In the standalone instance
ListFile->FetchFile->Outputport
In the NCM of the cluster
RPG(Standalone NIFI Instance)-->RPG(NIFI cluster)
Inputport->Routetext->PutHDFS(This is the processing done in the main cluster)
Let me know if you need any other information.Any inputs will be appretiated.
Regards,
Indranil Roy
Created on 09-06-2016 04:45 PM - edited 08-19-2019 03:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The output from the SplitText and RouteText processors is a bunch of FlowFiles all with the same filename (filename of the original FlowFile they were derived from.) NiFi differentiates these FlowFiles by assigning each a Unique Identifier (UUID). The problem you have is then writing to HDFS only the first FlowFile written with a particular filename is successful. All others result in the error you are seeing. The MergeContent processor you added reduces the impact but does not solve your problem. Remember that nodes do not talk to one another or share files with one another. So each MergeContent is working on its own set of files all derived from the same original source file and each node is producing its own merged file with the same filename. The first node to successfully write its file HDFS wins and the other nodes throw the error you are seeing. What is typically done here is to add an UpdateAttribute processor after each of your MergeContent processor to force a unique name on each of the FlowFiles before writing to HDFS.
The uuid that NiFi assigns to each of these FlowFiles is often prepended or appended to the filename to solve this problem:

If you do not want to merge the FlowFiles, you can simply just add the UpdateAttribute processor in its place. YOu will just end up with a larger number of files written to HDFS.
Thanks,
Matt
Created 08-24-2016 03:43 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Just to clarify on how S2S works when communicating with a target NiFi cluster. The NCM never receives any data so it cannot act as the load-balancer. When the source NiFi communicates with the NCM, the NCM returns a list of all currently connected nodes and there S2S ports along with the current load on each node to the source NiFi. It is then the job of the source NiFi RPG to use that information to do a smart load-balanced delivery of data to those nodes.
Created 08-25-2016 08:23 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Appreciate the correction 😉
Created 08-31-2016 12:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We have a single large(in TB's) flowfile coming to a standalone node.We want to distribute the processing.Is it a good approach to split the file into multiple smaller files using SplitText processor so that the processing is distributed to the remaining clusters.
In such a case we are considering the the flow given below:
In the NCM of the cluster
input->RouteText->PutHDFS
In the standalone processor that has the incoming flow file
ListFile->FetchFile->SplitText->UpdateAttribute->RPG(NCM url)
Does this set up ensure the processing to be distributed?
Created 08-31-2016 01:28 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@INDRANIL ROY That is the exact approach I suggested in response to the above thread we had going. Each Node will only work on the FlowFile it has in its possession. By splitting this large TB file into many smaller files, you can distribute the processing load across your downstream cluster. The distribution of FlowFiles via the RPG works as follows. The RPG communicates with the NCM of your NiFi cluster. The NCM returns back to the source RPG a list of available Nodes and there S2S ports in its cluster along with the current load on each. It is then the responsibility of the RPG to do smart load-balancing of the data in its incoming queue to these Nodes. Nodes with higher load will get fewer FlowFiles. The load balancing is done in batches for efficiency, so under light load you may not see an exact balanced delivery, but under higher FlowFile volumes you will see a balanced delivery over the 5 minutes delivery statistics.
Thanks,
Matt
Created on 09-02-2016 01:19 PM - edited 08-19-2019 03:44 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks @mclark for your input.
As suggested we implemented the data flow as shown below:
1)The standalone flow(This is where the single source file arrive).The RPG in this flow refers to the cluster i.e NCM url

2)The NCM of the cluster has flow as shown below:

3)In this approach were facing the error as shown below as getting only a subset of the records in HDFS

4)So to avoid the situation we used a MergeContent processor to merge the flowfiles since we were splitting them before loading them to HDFS

5)We configured the MergeContent in the way as shown below:

But even after this implementation we are not getting all the records in HDFS.
The source file has 10000000 records and approximately 5000000 records should go to each HDFS directory. But we are getting around 1000000 records in each Target and the error as shown below in the PutHDFS processors.
We are getting the same error as mentioned in the snapshot attached with the point 3 above.
Are we missing something very intrinsic here? Is there something wrong with the design?
We are using a 3 node cluster with NCM and 2 slave nodes. And the source file is coming to a standalone server.
Let me know if you need any other information. Any inputs would be appreciated.
Regards,
Indranil Roy
Created 09-02-2016 02:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please share how you have your SplitText and RouteText processors configuration.
If understand your end goal, you want to take this single files with 10,000,000 entries/lines and route only lines meeting criteria 1 to one putHDFS while route all other lines to another putHDFS?
Thanks,
Matt
Created 09-02-2016 05:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Our RouteText processor is configured as shown below
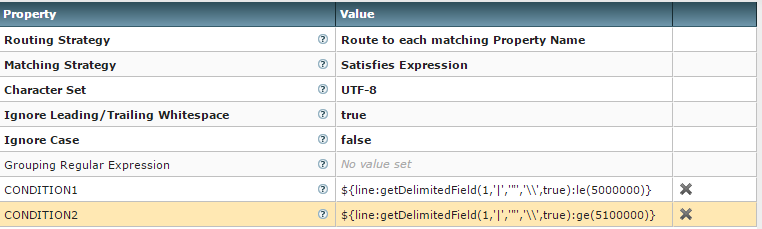{kind=link}
as it shows, records with (first field is record number) number <= 5000000 goes to one direction and records number >= 5100000 goes to another.
The split Text processor is configured with the below properties:
{kind=link}
Just to give an overview of our requirement:
1)We have a single file as source coming to a standalone server.
2)We fetch the file and then split it into multiple files and then send to the cluster in order to distribute the processing to all the nodes of the cluster.
3)In the cluster we route the files based on condition so that records with (first field is record number) number <= 5000000 goes to one output directory in HDFS and records number >= 5100000 goes to another output directory in HDFS as mentioned in the two putHDFS processors.
4)But after executing the process we have around 1000000 records in each output directory whereas ideally we should have 5000000 records approximately in either of the HDFS directory.
Also we are getting below error in the PutHDFS processors
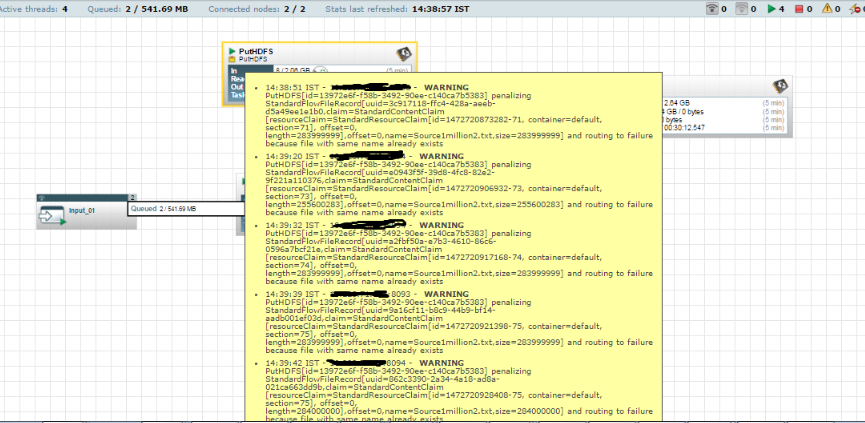{kind=link}
Please let me know if you need any further information.
Just to add to the above set up works perfectly fine when we are using a standalone node and we are using putFile instead of putHDFS to output the files to a local path instead of hadoop.
Regards,
Indranil Roy
Created 09-06-2016 03:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your approach above looks good except you really want to split that large 50,000,000 line file in to many more smaller files. Your example shows you only splitting it in to 10 files which may not ensure good file distribution to the downstream NiFi cluster nodes. The RPG load balances batches of files (up to 100 at a time) for speed and efficiency purposes. With so few files it is likely that every file will still end up on the same downstream node instead of load balanced. However if you were to split the source file in to ~5,000 files, you would achieve much better load-balancing.
Thanks,
Matt
Created 09-06-2016 04:05 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sure I will try that option.I can understand that I need to increase my split count in order to achieve better load balancing.But if I go back to the main issue I pointed in the thread above was that apart from the performance aspect we were getting only a subset of records in HDFS. It seems the process was trying to create the same file and overwrite it multiple times hence giving an error as shown below. When I use splitText processor and send it to the RPG and then merge it I am getting the error as shown(attached).
{kind=link}
Just to be on the same page here my flow looks like below:
In the NCM of the cluster
{kind=link}
In the standalone cluster
{kind=link}
Does increasing the splitCount solve this problem?
Also is it necessary to use a MergeContent/UpdateAttribute if we use a splitText?Can't we achieve this flow without using the MergeContent/UpdateAttribute processor in the RPG?
Regards,
Indranil Roy
Created on 09-06-2016 04:45 PM - edited 08-19-2019 03:43 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The output from the SplitText and RouteText processors is a bunch of FlowFiles all with the same filename (filename of the original FlowFile they were derived from.) NiFi differentiates these FlowFiles by assigning each a Unique Identifier (UUID). The problem you have is then writing to HDFS only the first FlowFile written with a particular filename is successful. All others result in the error you are seeing. The MergeContent processor you added reduces the impact but does not solve your problem. Remember that nodes do not talk to one another or share files with one another. So each MergeContent is working on its own set of files all derived from the same original source file and each node is producing its own merged file with the same filename. The first node to successfully write its file HDFS wins and the other nodes throw the error you are seeing. What is typically done here is to add an UpdateAttribute processor after each of your MergeContent processor to force a unique name on each of the FlowFiles before writing to HDFS.
The uuid that NiFi assigns to each of these FlowFiles is often prepended or appended to the filename to solve this problem:
If you do not want to merge the FlowFiles, you can simply just add the UpdateAttribute processor in its place. YOu will just end up with a larger number of files written to HDFS.
Thanks,
Matt

