Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: NiFi MergeContent with Defrag
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
NiFi MergeContent with Defrag
- Labels:
-
Apache NiFi
Created 01-23-2017 08:33 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, I am using Nifi 1.0.0 and am trying to merge records from an ExecuteSql processor using MergeContent.
I wanted to try Defrag merge strategy and have the following setup in an upstream UpdateAttribute processor for each flow file:
1. fragment.identifier - mmddyy of the flow file
2. fragment.index - nextInt()
3. fragment.count - executesql.row.count
4. segment.original.filename - filename
When i run the workflow - i get this error :
Cannot Defragment FlowFiles with Fragment Identifier because the expected number of fragments is <sql record count> but found only 1 fragments. It seems like MergeContent is trying to merge too soon - appreciate any advice.
My workflow is
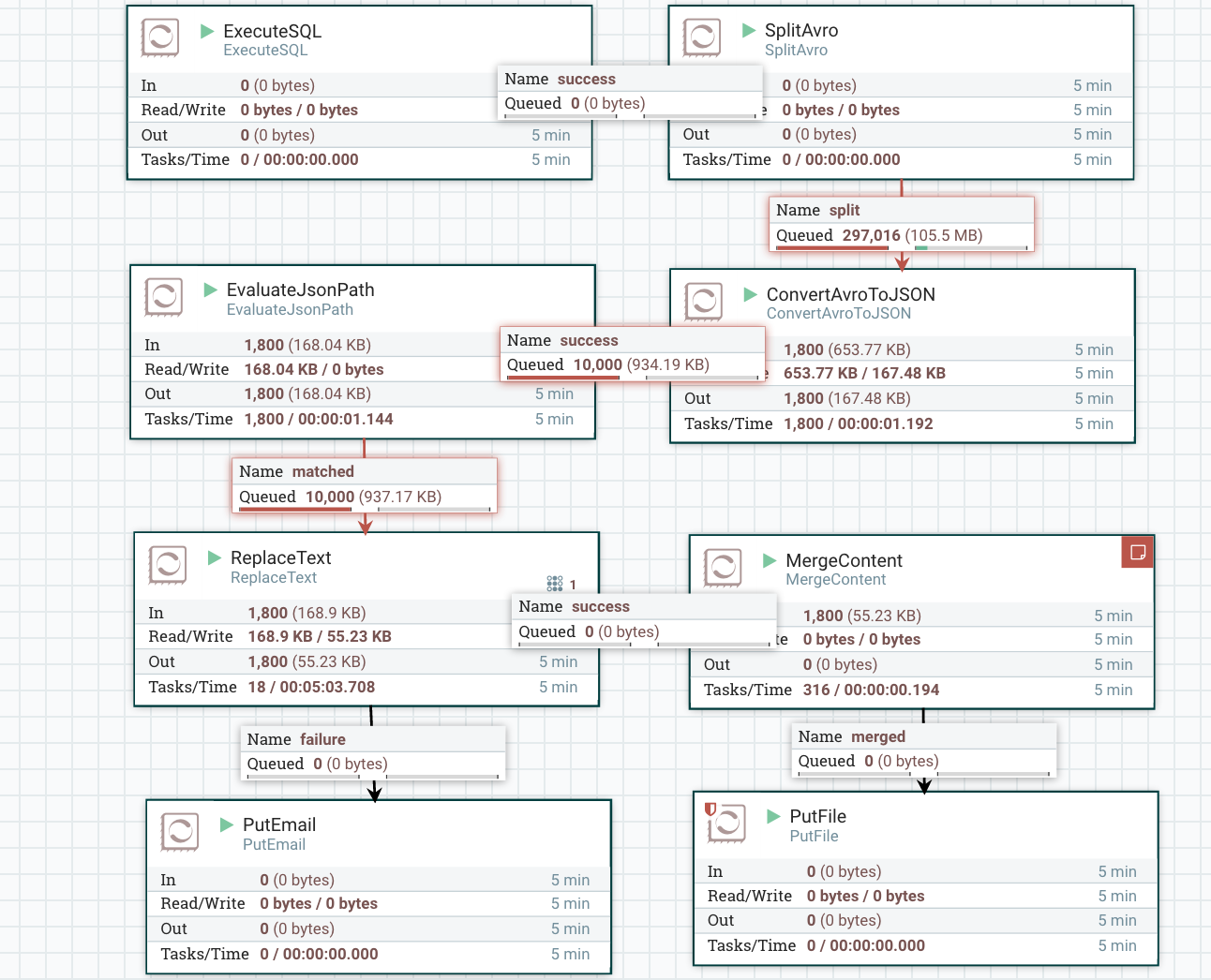
ExecuteSql -> SplitAvro -> UpdateAttribute (adds fragment.* attribute - could not see these on SplitAvro even though doc indicates it should be present) -> ConvertAvroToJson -> EvaluateJsonPath (to extract only some sql columns) -> ReplaceText(for conversion to comma delimited) -> MergeContent -> PutFile
NOTE: I got inconsistent file lengths when trying out various MergeContent Bin-packing configurations so turned to Defrag.
thanks
Created 01-23-2017 09:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The defragment mode of MergeContent is meant to work with upstream processors that have "fragmented" a flow file and produce the standard fragment attributes (fragment.identifier, fragment.index, fragment.count). In your example, SplitAvro is one of those processors that takes a flow file and fragments its content, but it didn't originally produce the fragment attributes . It was updated in Apache NiFi 1.1.0 (https://issues.apache.org/jira/browse/NIFI-2805) to add the fragment attributes, so if you upgrade then you should see them.
Created 01-23-2017 09:51 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The defragment mode of MergeContent is meant to work with upstream processors that have "fragmented" a flow file and produce the standard fragment attributes (fragment.identifier, fragment.index, fragment.count). In your example, SplitAvro is one of those processors that takes a flow file and fragments its content, but it didn't originally produce the fragment attributes . It was updated in Apache NiFi 1.1.0 (https://issues.apache.org/jira/browse/NIFI-2805) to add the fragment attributes, so if you upgrade then you should see them.
Created 01-23-2017 09:57 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thank you, Bryan!
Created 01-24-2017 09:47 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I now see the fragment.* attributes in SplitAvro on upgrading to 1.1.1 but still have the issue with x number of fragments expected and y found where x>y in MergeContent. The fragment.identifier and index for a sampling of files is unique. Wondering again if this is back pressure related. Appreciate any help, please let me know if i should open a different thread.
Created 01-24-2017 10:15 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There fragment.identifier should represent the overall flow file, so if there was an Avro data file with 1,000 records, there would be 1 identifier for that groups those thousand records together, and then there would be indexes 1 to 1000. Is that not the behavior you are seeing? Can you share a template of your flow?
Created 01-25-2017 04:51 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
mergecontentissue-template.pngmergecontentconfig.png
{kind=link}
{kind=link}
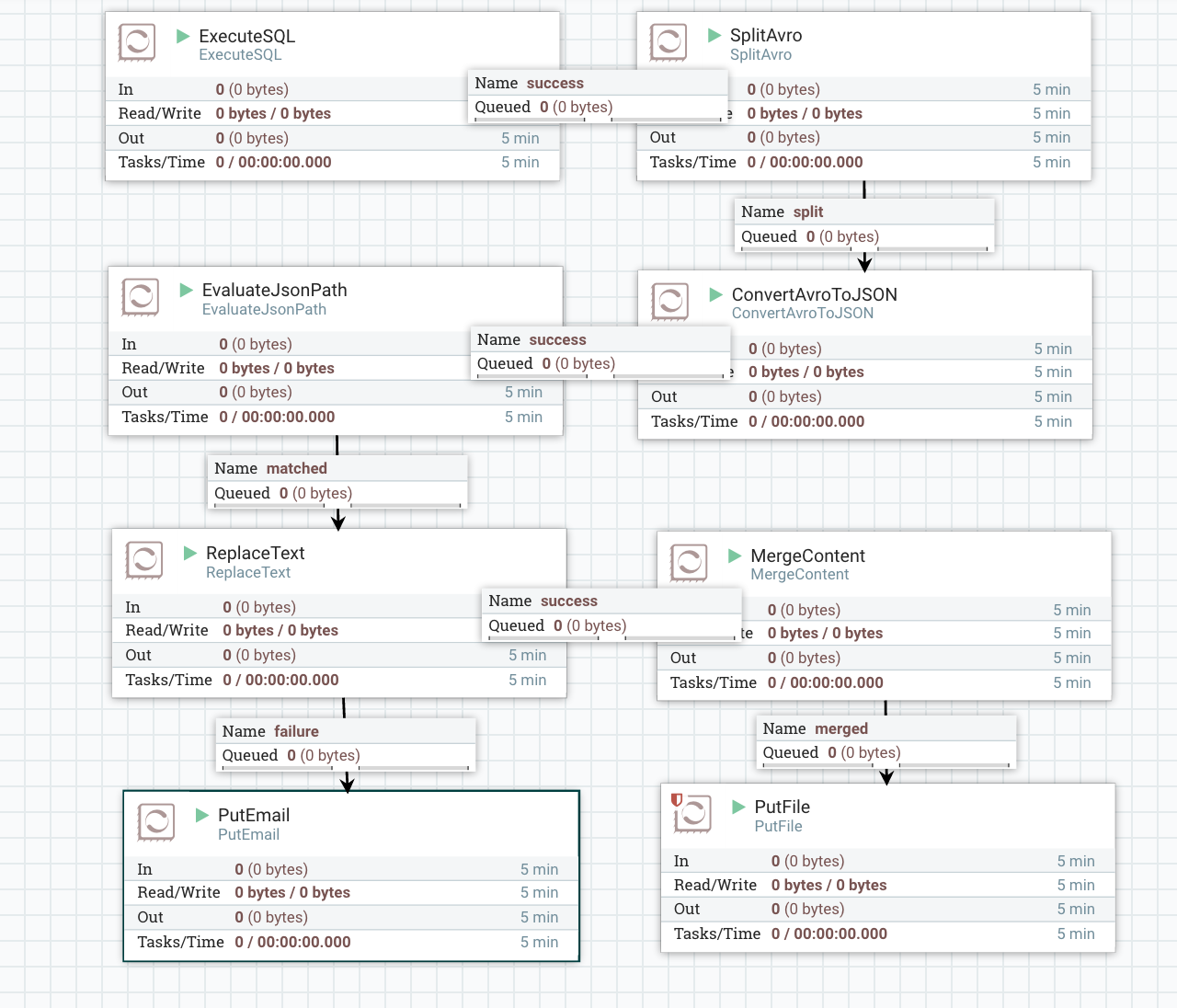
My sql query returns about 325K records, so in my latest run set my min entries to that(could not use ${executesql.row.count} - MergeContent complained that it wasn't an integer) and max to an arbitrary 500K with 100 bins.
I set run schedule as 60 minutes and on the incoming connect I set back pressure number of objects to 400K and back pressure data size to 1GB.
The fragment.identifier is the same across the flow files and the fragment.index does look different and less than 325k for some files i sampled in provenance history. I am currently running this configuration, but wanted to share to get your feedback.
Created 01-25-2017 02:55 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
An update - with this configuration, my workflow did not complete even 7 hours later, but MergeContent had not kicked off yet either so no fragment errors. Appreciate any suggestions.
Created 01-25-2017 03:10 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So just to recap the scenario, ExecuteSQL should be producing 1 flow file with 325k records in Avro, then SplitAvro (assuming Output Size is 1) produces 325k flow files with 1 Avro record each. Each of these split flow files should have:
- fragment.identifier - a unique id representing the overall batch of 325k flow files, this should be same on all 325k flow files
- fragment.count - the total number of fragments with in the fragment.identifier, this should be 325k in your case
- fragment.index - the index for the given flow with in the 325k fragments, so this should be different on each flow file and should be values like 1 - 325k
When using Defrag mode you don't need to set Min/Max Number of Entries, it is going to be based off the attributes above, so you can leave those at 1 and blank respectively. Each fragment identifier will equate to 1 bin, so the number of bins only has to be equal to or greater than the number of fragment.identifiers processed concurrently, it may only be 1 in your case. I'm not sure that you need the run duration set so high to 60 mins, the processor can run frequently and just won't do anything until seeing all the records for the fragment.
Created 01-25-2017 03:16 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is template that demonstrates the behavior on a much smaller scale:
GenerateFlowFile produces a flow file every 10 seconds with 3 lines of text, SplitText splits each line into 3 flow files, MergeContent defrags it back into 1 flow file, and LogAttribute logs the payload to nifi-app.log.
Created 01-25-2017 05:41 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Bryan - I changed to use 1 bin, 0 sec run duration and 1 min/ no max and now get the fragment error once again. Also reset the backpressure object threshold back to 10000. Not sure what i am missing.screen-shot-2017-01-25-at-123644-pm.png
{kind=link}
"o.a.n.processors.standard.MergeContent MergeContent[id=a8a50e76-0159-1000-371d-9097f2bda225] Cannot Defragment FlowFiles with Fragment Identifier bd01dfda-a8f5-4d37-a587-f7fe853fed3f because the expected number of fragments is 325070 but found only 100 fragments; routing 100 FlowFiles to failure"screen-shot-2017-01-25-at-123911-pm.png
{kind=link}

