Support Questions
- Cloudera Community
- Support
- Support Questions
- 'NoneType' object has no attribute 'setJobGroup'
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
'NoneType' object has no attribute 'setJobGroup'
- Labels:
-
Apache Spark
-
Apache Zeppelin
Created 07-08-2017 03:06 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am running a Spark program through Zeppelin notebook. When I run the program for the first time, it runs perfectly fine, but when I run the program again with no changes it throws the error: 'NoneType' object has no attribute 'setJobGroup'.
Also whenever I make changes to the Interpreter settings the program runs fine for the first time but again fails for the second time. It is baffling me on why this error doesn't occur during first run after an Interpreter setting change but occurs ever other runs after first time. Attached are the Interpreter settings and error message.error.jpginterpreter-setting.jpg.
{kind=link}
{kind=link}
Created 07-11-2017 02:20 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Krishna Kumar you dont need to stop spark context when you are using zeppelin. can you remove sc.stop() line and try again?
Created 07-11-2017 06:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@ssattiraju thanks that actually works and I could re-run my program multiple times without modifying/re-starting my interpreter. The reason i had stop() is to make sure there is no idle sparkContext and we faced some issues previously where a sparkContext that was initiated would not be terminated and they would be left open too long. So in this scenario whenever we run any program, the program goes into pending state. Our Admins proposed to use close() to close the context after the successful execution of the program.
Now my question is if we again encounter a problem where a sparkContext that has been opened and left frozen (not terminated properly). How are we supposed to handle this scenario? I have attached the snapshot of the program that runs into pending state for your reference.pending.jpg
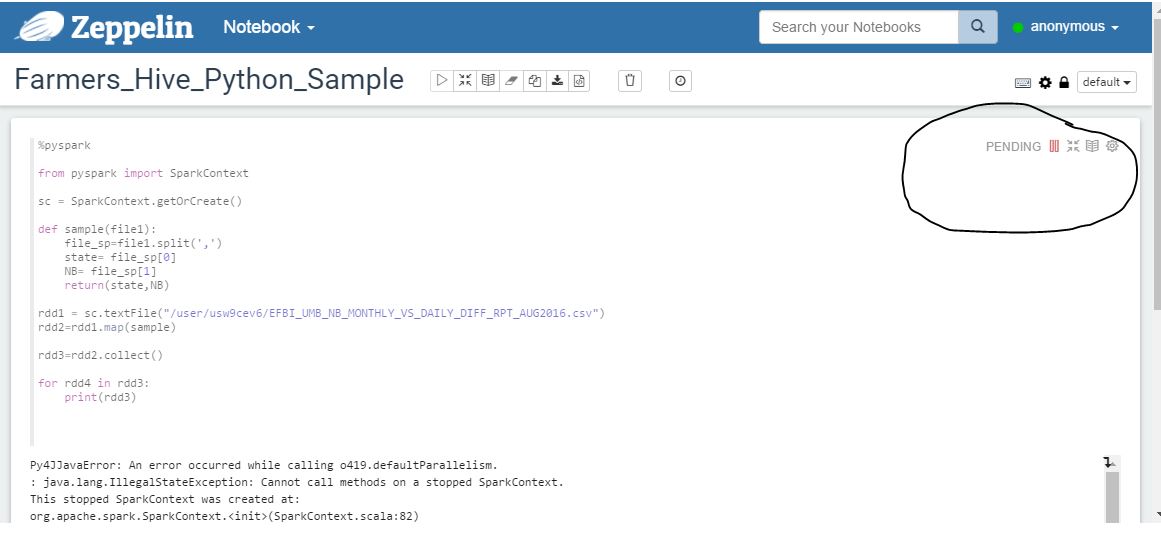{kind=link}
Created 07-12-2017 02:08 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
you can look into turning on `spark.dynamicAllocation.enabled` setting, this setting will release any un-unsed executors back to the cluster and request when they are needed link https://spark.apache.org/docs/latest/configuration.html#dynamic-allocation
or
after you have completed your analysis, you can restart the spark interpreter in zeppelin, due to lazy evaluation zeppelin will only start the spark context when you need it.

