Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: Pig:Input path does not exist Error
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Pig:Input path does not exist Error
- Labels:
-
Apache Pig
Created 08-16-2016 04:25 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I did following. (/tmp is under hdfs) . Please suggest how to resolve below issue
[root@sandbox /]# pig
grunt> lines= LOAD 'hdfs://sandbox.hortonworks.com:8020/tmp/mahi_dev/Data/count.txt' AS (line:chararray);
grunt> dump lines;
2016-08-16 15:41:17,892 [JobControl] INFO org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob - PigLatin:DefaultJobName got an error while submitting
org.apache.pig.backend.executionengine.ExecException: ERROR 2118: Input path does not exist: hdfs://sandbox.hortonworks.com:8020/tmp/mahi_dev/Data/count.txt
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigInputFormat.getSplits(PigInputFormat.java:279)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob.submit(ControlledJob.java:335)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.pig.backend.hadoop23.PigJobControl.submit(PigJobControl.java:128)
at org.apache.pig.backend.hadoop23.PigJobControl.run(PigJobControl.java:194)
at java.lang.Thread.run(Thread.java:745)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher$1.run(MapReduceLauncher.java:276)
Caused by: org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://sandbox.hortonworks.com:8020/tmp/mahi_dev/Data/count.txt
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigTextInputFormat.listStatus(PigTextInputFormat.java:36)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigInputFormat.getSplits(PigInputFormat.java:265)
... 18 more
2016-08-16 15:41:17,906 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1469722152838_0058
2016-08-16 15:41:17,906 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases lines
2016-08-16 15:41:17,906 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: lines[1,7],lines[-1,-1] C: R:
2016-08-16 15:41:17,919 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete
2016-08-16 15:41:22,943 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Ooops! Some job has failed! Specify -stop_on_failure if you want Pig to stop immediately on failure.
2016-08-16 15:41:22,943 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - job job_1469722152838_0058 has failed! Stop running all dependent jobs
2016-08-16 15:41:22,943 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2016-08-16 15:41:23,123 [main] INFO org.apache.hadoop.yarn.client.api.impl.TimelineClientImpl - Timeline service address: http://sandbox.hortonworks.com:8188/ws/v1/timeline/
2016-08-16 15:41:23,124 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at sandbox.hortonworks.com/10.0.2.15:8050
2016-08-16 15:41:23,292 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Could not get Job info from RM for job job_1469722152838_0058. Redirecting to job history server.
2016-08-16 15:41:24,297 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: sandbox.hortonworks.com/10.0.2.15:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=50, sleepTime=1000 MILLISECONDS)
2016-08-16 15:41:25,300 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: sandbox.hortonworks.com/10.0.2.15:10020. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=50, sleepTime=1000 MILLISECONDS)
Created 08-17-2016 06:09 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Looks like your job history server is down or not responding.
Can you please check the status in Ambari UI and bring it up if its down?
Created 08-16-2016 10:10 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please paste output of
hdfs dfs -ls /tmp/mahi_dev/Data/
Created 08-16-2016 10:13 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
[root@sandbox /]# hdfs dfs -ls /tmp/mahi_dev/Data/
ls: `/tmp/mahi_dev/Data/': No such file or directory
Created 08-16-2016 10:24 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Well there's your answer, you did not upload the file or placed it in the wrong directory
hdfs dfs -mkdir /tmp/mahi_dev hdfs dfs -mkdir /tmp/mahi_dev/Data hdfs dfs -put count.txt /tmp/mahi_dev/Data/
Created 08-16-2016 10:27 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
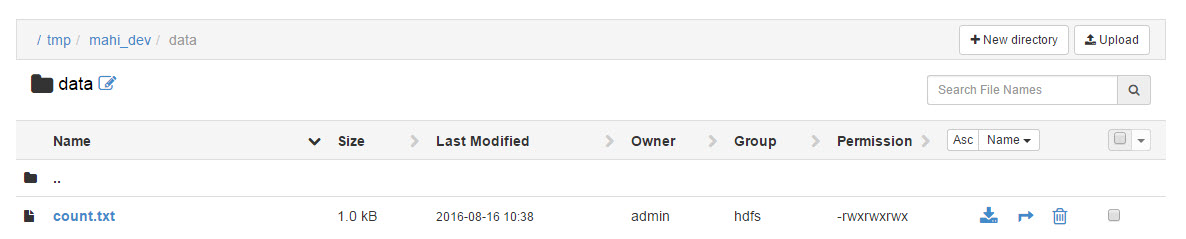{kind=link}
But I have file in my hdfs file system. PFA Ambari screenshot.
Created 08-16-2016 11:02 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Path is /tmp/mahi_dev/data
Lower case data my friend and you ran with upper
Created 08-17-2016 03:46 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks @ Artem Ervits. 1st error is resolved. I didnot realized about upper case.
But I am still facing 2nd issue. How to resolve it?
2016-08-17 03:40:46,656 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at sandbox.hortonworks.com/10.0.2.15:8050 2016-08-17 03:40:46,664 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server 2016-08-17 03:40:47,671 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: sandbox.hortonworks.com/10.0.2.15:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=50, sleepTime=1000 MILLISECONDS) 2016-08-17 03:40:48,672 [main] INFO org.apache.hadoop.ipc.Client - Retrying connect to server: sandbox.hortonworks.com/10.0.2.15:10020. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=50, sleepTime=1000 MILLISECONDS)
Created 08-17-2016 06:09 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Looks like your job history server is down or not responding.
Can you please check the status in Ambari UI and bring it up if its down?
Created 08-17-2016 02:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for your help. Its working now.

