Support Questions
- Cloudera Community
- Support
- Support Questions
- Re: YARN Applications wait for long time in Accept...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Float this Question for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
YARN Applications wait for long time in Accepted State
- Labels:
-
Apache YARN
Created 08-10-2018 01:49 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello All,
We are using HDP-2.5.6 in Production cluster. We have 5 queues configured in capacity scheduler.
We have given 840 GB of total memory to Yarn. Preemption is enabled for all queue.
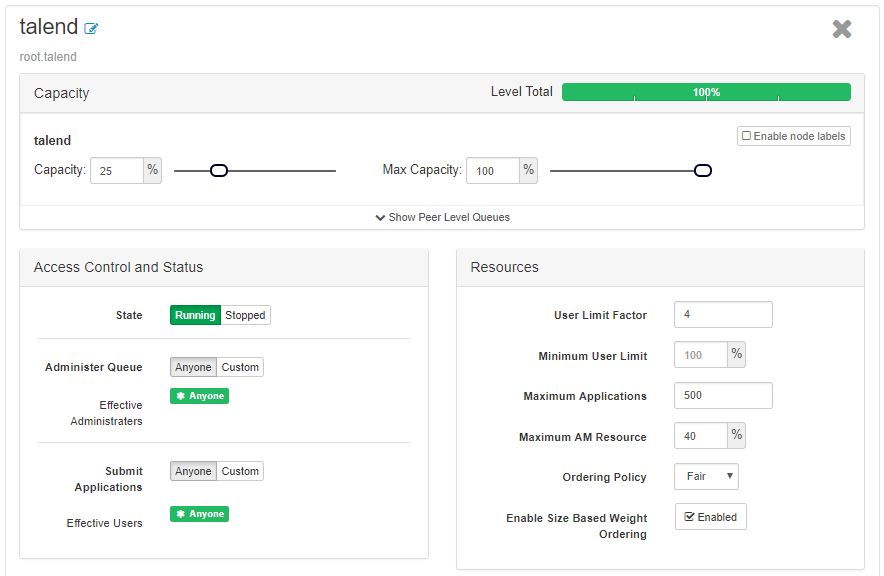
Out of that for 'talend' queue we have given 25% as min capacity and 100% as max capacity. Attached screenshot for 'talend' queue talend-queue.png.
{kind=link}
The problem is, though 'talend' queue has lot of resources available applications are going into accepted state for long time. Attached screenshot for accepted application accepted-application.png. Some applications are even in accepted state for more that 5 hours.
{kind=link}
Diagnostic section is showing wrong AM resource.
In ResourceManager logs, we are getting following message:
2018-08-10 06:12:13,129 INFO capacity.LeafQueue (LeafQueue.java:activateApplications(662)) - Not activating application application_1529949441873_131872 as amIfStarted: <memory:348160, vCores:85> exceeds amLimit: <memory:344064, vCores:1> 2018-08-10 06:12:13,129 INFO capacity.LeafQueue (LeafQueue.java:activateApplications(662)) - Not activating application application_1529949441873_131873 as amIfStarted: <memory:348160, vCores:85> exceeds amLimit: <memory:344064, vCores:1> 2018-08-10 06:12:13,129 INFO capacity.LeafQueue (LeafQueue.java:activateApplications(662)) - Not activating application application_1529949441873_131874 as amIfStarted: <memory:348160, vCores:85> exceeds amLimit: <memory:344064, vCores:1>
We have AM resources available in queue but it shows exceeds amLimit message. Also amLimit is not correct.
Why applications are going in accepted state though we have lot of resources available at queue level?
Please suggest.
Created 08-16-2018 12:12 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Resource Manager Restart cleans cache of RM and resolves issue.
Created 08-12-2018 04:37 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Sandeep Nemuri @Arti Wadhwani Please suggest.
Created 08-12-2018 06:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It seems as if you crossed a vCore limit - not memory.
In Yarn Queue Manager what calculator are you using ? Default or Dominant ? If Dominant - swithc to Default.
In Ambari >>> Yarn >>> Configs >>> Settings - make sure CPU Scheduling & CPU Isolation are off (unless you have switched them on intentionally and you are using cGroups accordingly).
Also in In Ambari >>> Yarn >>> Configs >>> Settings make sure you sufficient "number of virtual cores" & "Maximum Container Size" (it should be the number of cores you have in your datanodes minus 4-6 cores for OS).
Created 08-16-2018 12:12 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Resource Manager Restart cleans cache of RM and resolves issue.
- « Previous
-
- 1
- 2
- Next »

