Environment:
We are using EMR, with Spark 2.1 and EMR FS.
Process we are doing:
We are running a PySpark job to join 2 Hive tables and creating a another hive table based on this result using saveAsTable and storing it as a ORC with partitions
Issue:
18/01/23 10:21:28 INFO
OutputCommitCoordinator: Task was denied committing, stage: 84, partition: 901,
attempt: 10364
18/01/23 10:21:28 INFO
TaskSetManager: Starting task 901.10365 in stage 84.0 (TID 212686, ip-172-31-46-97.ec2.internal,
executor 10, partition 901, PROCESS_LOCAL, 6235 bytes)
18/01/23 10:21:28 WARN
TaskSetManager: Lost task 884.10406 in stage 84.0 (TID 212677,
ip-172-31-46-97.ec2.internal, executor 85): TaskCommitDenied (Driver denied
task commit) for job: 84, partition: 884, attemptNumber: 10406
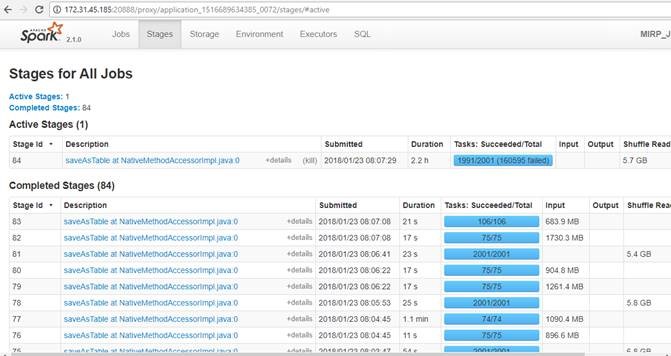
This specific log information is recursive from the Spark logs and by the time we killed the job we have seen this for about ~170000 (160595) times as given in spark-task-commit-denied.jpg
From the source code it shows this:
/** * :: DeveloperApi :: * Task requested the driver to commit, but was denied. */
@DeveloperApicase class TaskCommitDenied
( jobID: Int,
partitionID: Int,
attemptNumber: Int) extends TaskFailedReason {
override def toErrorString: String = s"TaskCommitDenied (Driver denied task commit)" +
s" for job: $jobID, partition: $partitionID, attemptNumber: $attemptNumber"
/** * If a task failed because its attempt to commit was denied, do not count this failure * towards failing the stage. This is intended to prevent spurious stage failures in cases * where many speculative tasks are launched and denied to commit. */
override def countTowardsTaskFailures: Boolean = false
}Please note we have not enabled spark.speculation i.e. (it is false) and from the spark job Environment we have not seen this property at all.
But while the job is running we can see that the corresponding files are created under EMRFS under the table temp directories like:
hdfs://ip-172-31-18-155.ec2.internal:8020/hive/location/hive.db/hivetable/_temporary/0/task_1513431588574_1185_3_01_000000/00000_0.orc
we can see these kind of folders about 2001 ( as we have given the spark.sql.shuffle.partitions = 2001)
Question(s):
1) What could cause the job to get launch ~170000 tasks even though we have not enabled spark.speculation
2) When it has completed writing the data to HDFS (EMRFS) why each executor is trying to launch new tasks
3) is there a way we can avoid this?
Thanks a lot for looking into this. any inputs related to this will help us a lot.
Venkat
{kind=link}

