Community Articles
- Cloudera Community
- Support
- Community Articles
- How Do I Distribute Data Across an Apache NiFi Clu...
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Created on 02-10-2016 07:27 PM - edited 08-17-2019 01:15 PM
In an Apache NiFi cluster, every node runs the same dataflow and data is divided between the nodes. In order to leverage the full processing power of the cluster, the next logical question is - "how do I distribute data across the cluster?".
The answer depends on the source of data. Generally, there are sources that can push data, and sources that provide data to be pulled. This post will describe some of the common patterns for dealing with these scenarios.
Background
A NiFi cluster is made up of a NiFi Cluster Manager (NCM) and one or more nodes. The NCM does not perform any processing of data, but manages the cluster and provides the single point of access to the UI for the cluster. In addition, one of the processing nodes can be designated as a Primary Node. Processors can then be schedule to run on the Primary Node only, via an option on the scheduling tab of the processor which is only available in a cluster.
When connecting two NiFi instances, the connection is made with a Remote Process Group (RPG) which connects to an Input Port, or Output Port on the other instance.
In the diagrams below, NCM will refer to the cluster manager, nodes refer to the nodes processing data, and RPG refers to Remote Process Groups.
Pushing
When a data source can push it's data to NiFi, there will generally be a processor listening for incoming data. In a cluster, this processor would be running on each node. In order to get the data distributed across all of the listeners, a load balancer can be placed in front of the cluster, as shown in the following example:

The data sources can make their requests against the url of the load balancer, which redirects them to the nodes of the cluster. Other processors that could be used with this pattern are HandleHttpRequest, ListenSyslog, andListenUDP.
Pulling
If the data source can ensure that each pull operation will pull a unique piece of data, then each node in the NiFi cluster can pull independently. An example of this would be a NiFi cluster with each node running a GetKafka processor:

Since each GetKafka processor can be treated as a single client through the Client Name and Group ID properties, each GetKafka processor will pull different data.
A different pulling scenario involves performing a listing operation on the primary node and distributing the results across the cluster via site-to-site to pull the data in parallel. This typically involves "List" and "Fetch" processor where the List processor produces instructions, or tasks, for the Fetch processor to act on. An example of this scenario is shown in the following diagram with ListHDFS and FetchHDFS:

ListHDFS is scheduled to run on primary node and performs a directory listing finding new files since the last time it executed. The results of the listing are then sent out ListHDFS as FlowFiles, where each FlowFile contains one file name to pull from the HDFS. These FlowFiles are then sent to a Remote Process Group connected to an Input Port with in the same cluster. This causes each node in the cluster to receive a portion of the files to fetch. Each FetchFile processor can then fetch the files from HDFS in parallel.
Site-To-Site
If the source of data is another NiFi instance (cluster or standalone), then Site-To-Site can be used to transfer the data. Site-To-Site supports a push or pull mechanism, and takes care of evenly pushing to, or pulling from, a cluster.
In the push scenario, the destination NiFi has one or more Input Ports waiting to receive data. The source NiFi brings data to a Remote Process Group connected to an Input Port on the destination NiFi.

In the pull scenario, the destination NiFi has a Remote Process Group connected to an Output Port on the source NiFi. The source NiFi brings data the Output Port, and the data is automatically pulled by the destination NiFi.

NOTE: These site-to-site examples showed a standalone NiFi communicating with a cluster, but it could be cluster to cluster.

Created on 09-19-2016 12:29 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
in Site-to-Site scenario, is it possible to ensure equal distribution of flow file. May be in ListHDFS and FetchHDFS scenario ?
Created on 09-19-2016 12:41 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Yes, site-to-site handles this for you and distributes equally.
Created on 02-10-2017 07:08 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@Bryan Bende great article, it is very helpful to understand how things work in a Cluster environment; do you have plans to update the article with the new Zero-Master Clustering paradigm; for newbies like me, it would be helpful to know how things (what you described in the article) would change in the new zero-master cluster environment.
Created on 02-10-2017 08:24 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks! Since the NCM didn't do any data processing there is actually not much different for this article between 0.x and 1.x. The only real difference is when setting up site-to-site connections you now create a remote process group and use the URL of any node in the cluster, where as before you entered the URL of the NCM. Other than that just pretend the NCM isn't in the diagrams and you should be good to go.
Created on 02-10-2017 08:46 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Awesome, thanks for clarifying @Bryan Bende
Created on 01-10-2018 10:30 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Bryan,
Really nice and helpful article!
I am new to nifi and trying to use clustering for data pull scenario from SQL and Greenplum database servers. For this I was thinking the best approach for clustering will be similar to the hdfs example you've shown here. However, the part I am getting confused with is that, when I create an RPG its linking to another node of the cluster with the same data flow as the parent one(where the RPG is created), so it looks like an endless loop between first node feeding to 2nd node and back. So I am not sure, if I am doing it right thing? Moreover, the cluster is hanging when I do this, maybe its related to how we configured it, but still wanted to know if this is the way it should be done.
Do you know any place here where they might have sample/example xml dataflows with RPG?
Please let me know if you need more clarification on this?
Appreciate your help!
Thanks,
Samir
Created on 01-11-2018 05:42 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Hi Samir,
There shouldn't be an end-less loop...
As you can see in the HDFS example diagram, there are two parts to the flow:
- ListHDFS -> RPG (this part only runs on primary node)
- Input Port -> FetchHDFS -> rest of the flow (this part runs on all nodes)
The starting point of your flow should be something that has no input, like ListHDFS, so there can't be a circular loop back to that point.
The end of the second part should end with wherever you are sending your data, like PutHDFS for example, after that it is dead end, no loop back to anywhere.
If this is not clear, please provide a screen shot or template of your flow so we can see how you have connected the processors.
Thanks,
Bryan
Created on 01-12-2018 09:48 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Thanks for the response Bryan,
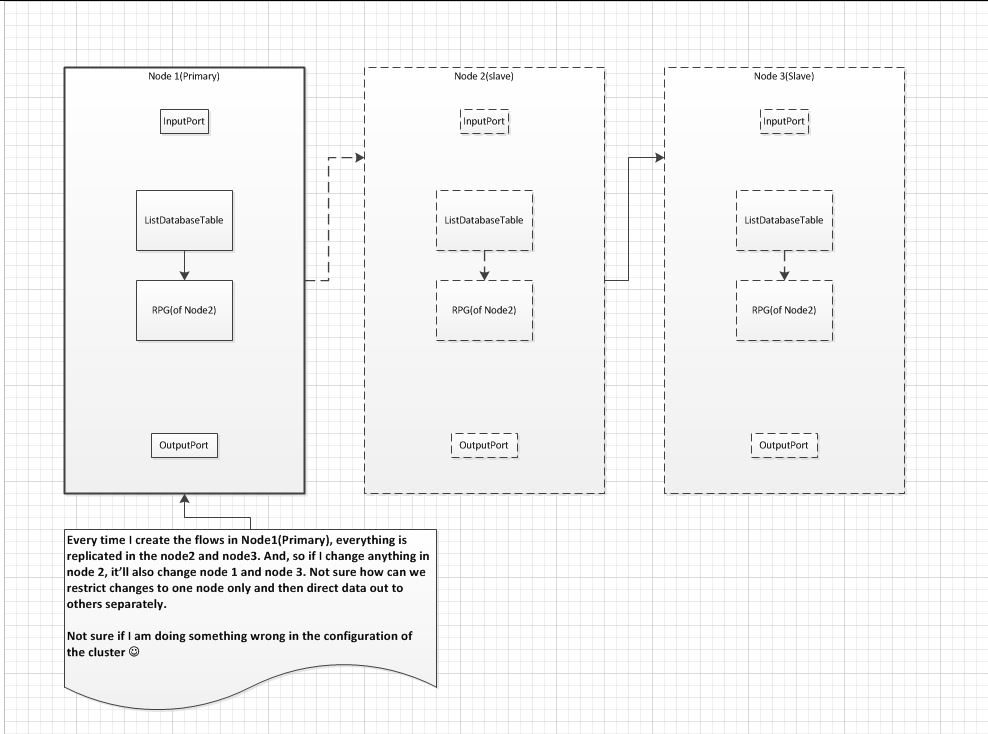
In the step ListHDFS -> RPG(this part only runs on primary node), the question is how do restrict this flow only to the primary node? Because whatever I create in one node is replicated in all the nodes, so when I create an RPG of say node2, its actually has the same flows as the node1 and then it looks like a loop. Actually, flows I have created are kind of complex and can't share it here, but I hope you understand what I am talking about through the diagram attached. I think we have to configure in a way that the primary node flows are not replicated in the slave nodes.
Really appreciate your help.
nifi-node-flow-replication-confusion.jpg
{kind=link}
Thanks,
Samir

| User | Count |
|---|---|
| 6 | |
| 4 | |
| 2 | |
| 1 | |
| 1 |
